静态表编码
静态表类型
静态表很简单,只包含已知的header字段。分为两种:
- name和value都可以完全确定,比如
:metho: GET、:status: 200- 该情况很好理解,已知键值对直接使用一个字符表示;
- 只能够确定name:比如
:authority、cookie- 此种情况稍微说明下:首先将
name部分先用一个字符(比如cookie)来表示,同时,根据情况判断是否告知服务端,将cookie: xxxxxxx添加到动态表中(我们这里默认假定是从客户端向服务端发送消息)
- 此种情况稍微说明下:首先将
静态表使用
HTTP/2 将 61 个高频出现的头部,比如描述浏览器的 User-Agent、GET 或 POST 方法、返回的 200 SUCCESS 响应等,分别对应 1 个数字再构造出 1 张表,并写入 HTTP/2 客户端与服务器的代码中。由于它不会变化,所以也称为静态表。
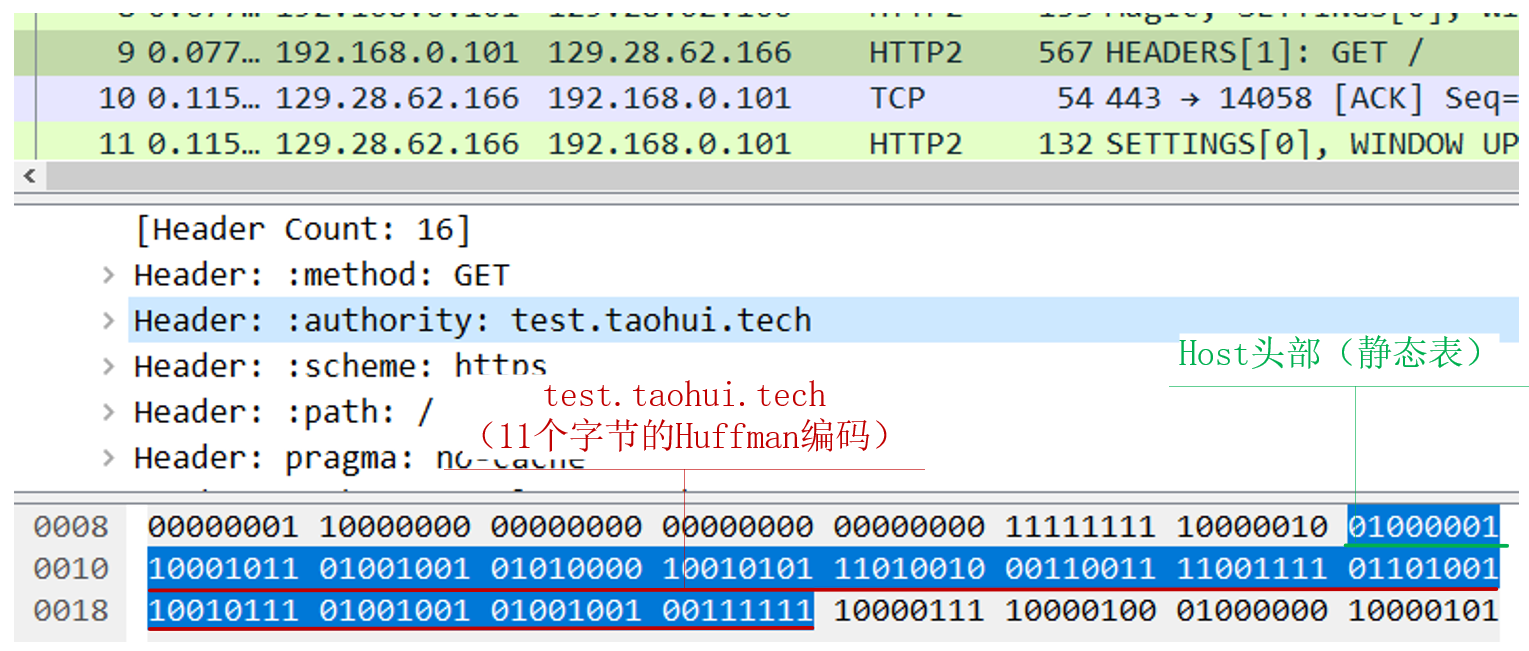
如上所示,这样收到 01000001 时,根据RFC7541 规范,前 2 位为 01 时,表示这是不包含 Value 的静态表头部:

再根据索引 000001 查到 authority 头部(Host 头部在 HTTP/2 协议中被改名为 authority)。紧跟的字节表示域名,其中首个比特位表示域名是否经过 Huffman 编码,而后 7 位表示了域名的长度。在本例中,10001011 表示域名共有 11 个字节(8+2+1=11),且使用了 Huffman 编码。
静态 Huffman 编码
根据信息论,高频出现的信息用较短的编码表示后,可以压缩体积。因此,在统计互联网上传输的大量 HTTP 头部后,HTTP/2 依据统计频率将 ASCII 码重新编码为一张表,参见这里。test.taohui.tech 域名用到了 10 个字符,我把这 10 个字符的编码列在下表中。
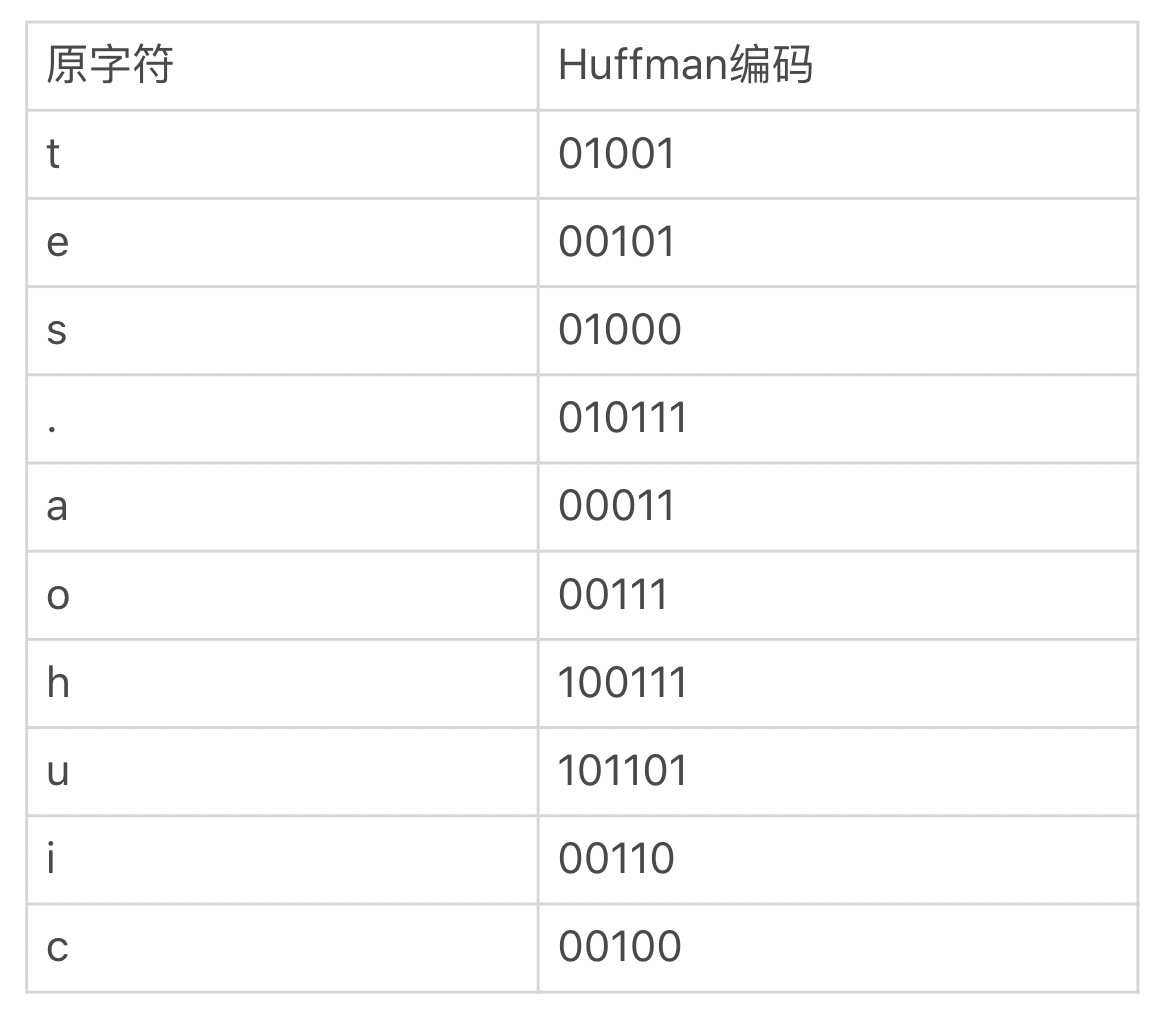
这样,接收端在收到下面这串比特位(最后 3 位填 1 补位)后,通过查表(请注意每个字符的颜色与比特位是一一对应的)就可以快速解码为:

由于 8 位的 ASCII 码最小压缩为 5 位,所以静态 Huffman 的最大压缩比只有 5/8
动态表编码
虽然静态表已经将 24 字节的 Host 头部压缩到 13 字节,但动态表可以将它压缩到仅 1 字节,这就能节省 96% 的带宽
当下许多页面含有上百个对象,而 REST 架构的无状态特性,要求下载每个对象时都得携带完整的 HTTP 头部。如果 HTTP/2 能在一个连接上传输所有对象,那么只要客户端与服务器按照同样的规则,对首次出现的 HTTP 头部用一个数字标识,随后再传输它时只传递数字即可,这就可以实现几十倍的压缩率。所有被缓存的头部及其标识数字会构成一张表,它与已经传输过的请求有关,是动态变化的,因此被称为动态表。
动态表内容
- 动态表最初是一个空表,当每次解压头部的时候,有可能会添加条目(比如前面提到的cookie,当解压过一次cookie时,
cookie: xxxxxxx就有可能被添加到动态表了,至于是否添加要根据后面提到的指令判断) - 动态表允许包含重复的条目,也就是可能出现完全相同的键值对
- 为了限制解码器的需求,动态表大小有严格限制的
动态表使用
静态表有 61 项,所以动态表的索引会从 62 起步。比如下图中的报文中,访问 test.taohui.tech 的第 1 个请求有 13 个头部需要加入动态表。其中,Host: test.taohui.tech 被分配到的动态表索引是 74(索引号是倒着分配的)
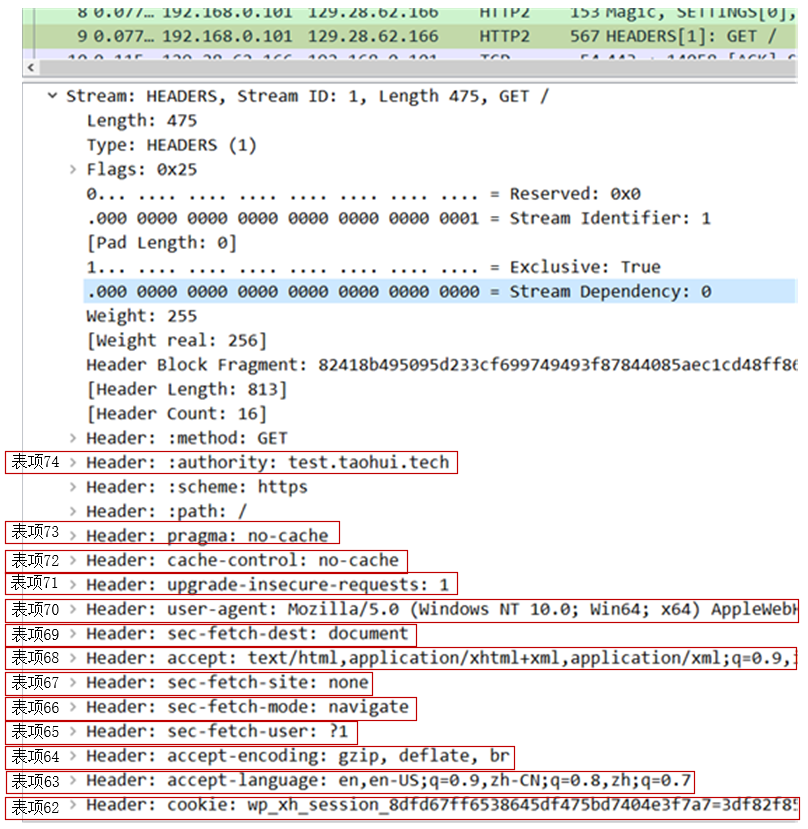
这样,后续请求使用到 Host 头部时,只需传输 1 个字节 11001010 即可。其中,首位 1 表示它在动态表中,而后 7 位 1001010 值为 64+8+2=74,指向服务器缓存的动态表第 74 项
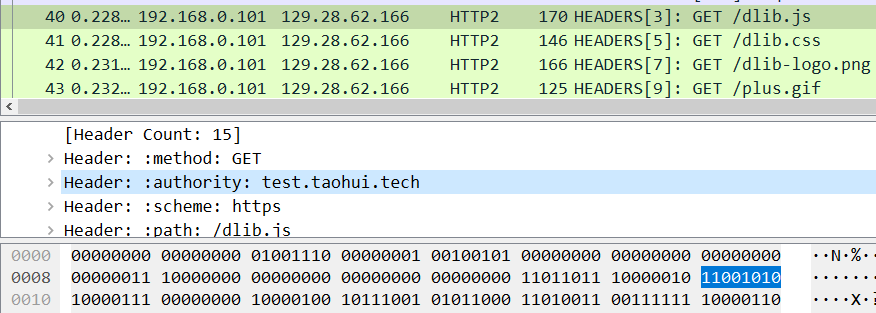
态索引表是需要连接双方维护的,其内容基于连接上下文,一个 HTTP2 连接有且仅有一份动态表
索引空间
静态表和动态表一起组成一个索引地址空间。设静态表长度为s,动态表长度为k,那么最终的索引空间如下:
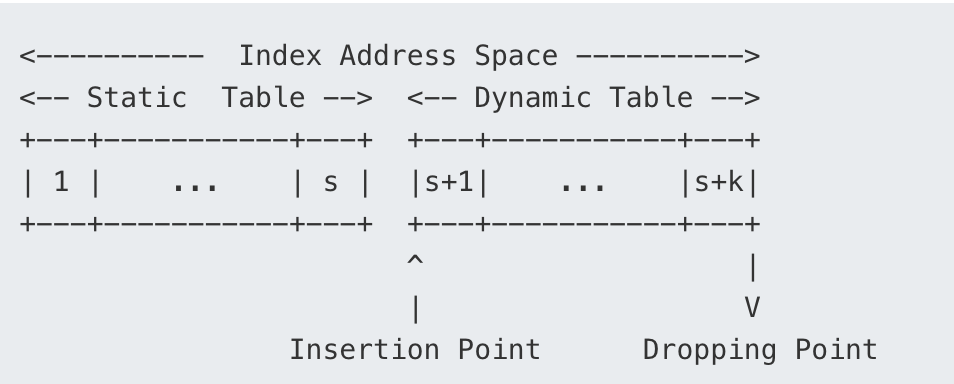
- 索引1-s是静态表,s-k是动态表,
- 新的条目从在动态表的开头插入,从动态表末尾移除
有了这个索引空间以后,header的字段一共有以下几种表示方法:
- 直接用索引值来表示(比如2表示method:get)
- 字段的name使用索引值表示,字段的value直接使用原有字面的值的八位字节序列或者使用静态Huffman编码表示
header字段表示法
数字表示法
数字主要用来表示上文中索引空间的索引值,具体的规则如下:
- 先用限定位数的前缀表示,如果范围足够那就直接表示(限定位数是指下图中的扣除xxx剩余的长度,xxx的具体含义见下一节-动态表更新指令以及表示)
- 如果范围不够大,那么接下来每次增加8个字节来表示
- 8个字节的最高位都作为标志位,表示是否要继续向下延续(解码的时候要用到)
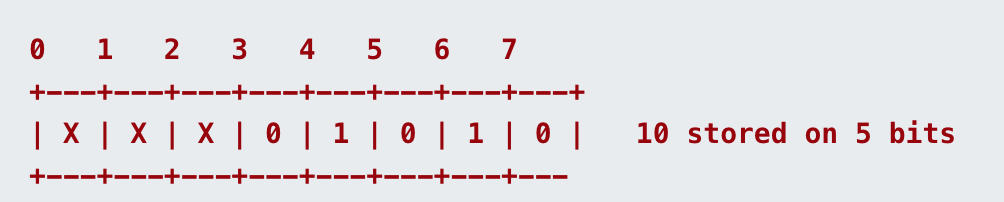
示例1-用5位前缀表示10
首先这里限制位数为5,由于10小于2^5-1,可以直接表示为01010,结果为:
示例2-用5位前缀表示1337
- 1337>2^5-1,那么前面5位只能表示到31,剩余1337-31 = 1306
- 接下来:1306>2^7 =128(八位字节第一位是标志位,所以表示范围只有2^7-1)
- I % 128 == 26,26用7位2进制表示是0011010,由于I >128 还需要继续延续,所以标志位取1,得到第二行应该是10011010
- I / 128 = 10,10用7位2进制表示是0001010,标志位取0即可所以最终结果如下:

示例3-直接从边界开始表示42
直接从边界开始,也就是使用8位前缀,42小于2^8-1=255 所以直接表示:

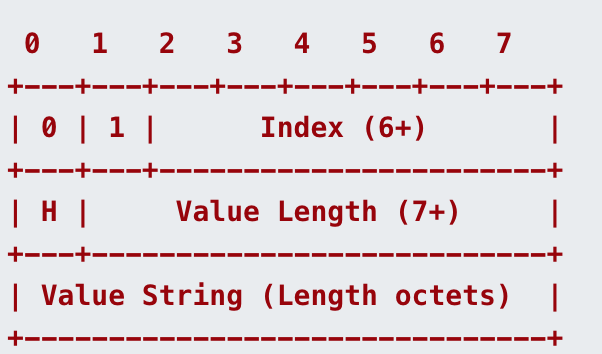
字条串表示法
header的字段可以用字符串文本来表示,具体的规则如下:

- H是一个标志位,表示该字符串的八位字节是否被哈夫曼编码过
- String Length:表示用于编码的字节位数,7位前缀表示法具体的规则同上述5位前缀表示法
- String Data:字符串编码过的数据,如果h为0,则编码数据是字符串文字的原始八位字节;如果H是“1”,则编码数据是字符串文字的huffman编码。
动态表更新指令
1. 整个键值对都在现有的索引空间中
这种情况下,第一个字节固定为1,然后用7位前缀法表示索引的值

例如10000010,表示索引值为2,查找静态表可知,对应的header字段是method:GET
索引空间地址是从1开始的,0的话会被视为错误,也就是10000000解码时会出错
2. name在索引空间,但是value不在,且需要更新动态表
这种情况下,前两位固定为01,后面6位表示索引值,取到对应的name,例如01010000对应32,查静态表可知name是cookie,接下来使用字符串表示法表示对应的value字段,在解码之后,这个字段就被加到动态表中,下次编码的时候会直接使用情况1,(这里也就说明了为什么后续请求压缩程度更大,因为动态表在不断扩充,扩充的界限请看官方文档这里暂时不说明)
3. name和value都不在索引空间,且需要更新动态表
这种情况和上面的很相似,只要补上name部分的字符串表示,并且把index值设置为0即可。

观察上述两种情况可知,如果需要更新动态表,前两位标志位都是01
4. name在索引空间,但是value不在,且不需要更新动态表
这种情况,前四位固定为0000,其他和情况2一致,

5. name和value都不在索引空间,且不需要更新动态表
同理,前四位固定为0000,其他和情况3一致,

观察上述两种情况,发现如果不需要更新动态表,则前四位固定为0000
6. name在索引空间,但是value不在,且绝对不允许更新动态表
这种情况下和情况4基本一致,只是前四位固定为0001,区别在于:
- 不需要更新表示,本次的发送过程不更新该字段到动态表;如果有多次转发,那么并不对转发做要求
- 绝对不允许更新表示,如果这个请求被多次转发才到目标,那么转发的所有中间对于该字段也必须采用相同的处理方案

7. name和value都不在索引空间,且绝对不允许更新动态

和上面一种情况同理,就略过了。
实例分析
接下来抓一些请求来看看具体的内容,比如直接抓取segment下的请求
method字段
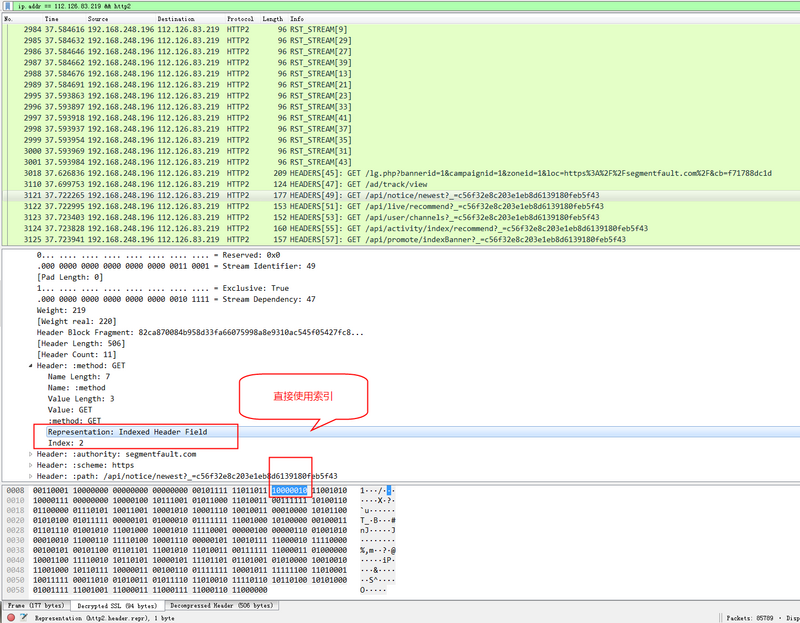
在这里method字段,就是前面提到的情况1--直接在静态表查询就可以得到整个键值对,对应的索引值为2。 查看底下的编码10000010,第一位1表示整个键值对在索引空间存在,后面的0000010=2表示索引地址。
authority
- 第一次请求
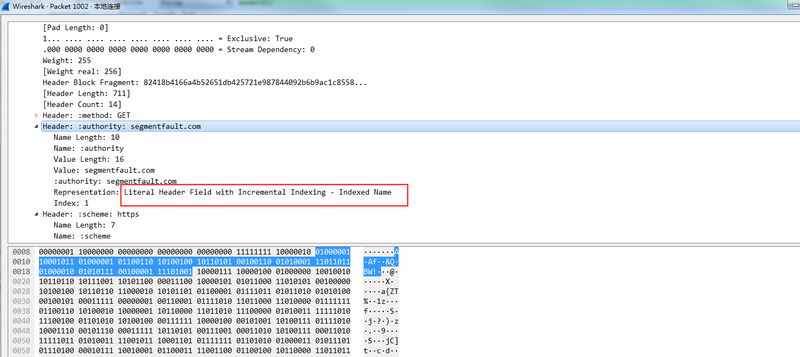
可以看出,这个字段符合前面提到的情况2:第一次编码是01000001,表示name直接使用索引,索引值为1,且value不在索引空间中,后面的部分表示具体的value值
- 第二次请求
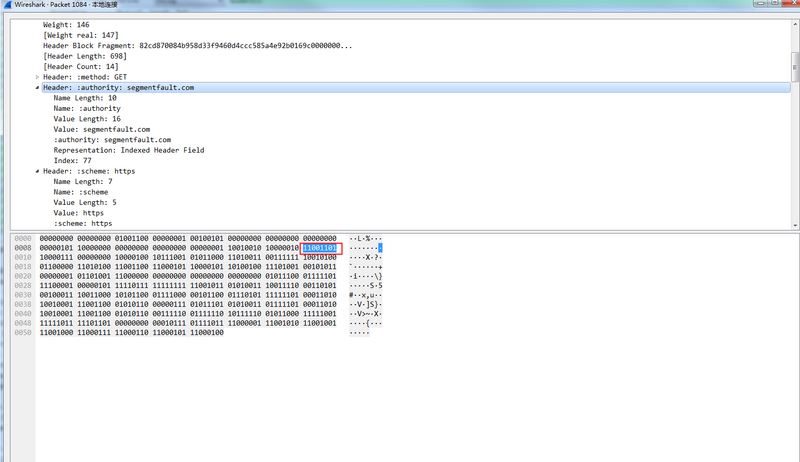
发现已经是直接使用索引空间的值(因为前一次请求已经要求更新到动态表),所以本次只要一个字符长度直接表示这个字段11001101,第一个1表示情况1,后面1001101=64+8+4+1 =77 也就是此时对应的索引值
并发传输请求
HTTP/1.1 中的 KeepAlive 长连接虽然可以传输很多请求,但它的吞吐量很低,因为在发出请求等待响应的那段时间里,这个长连接不能做任何事!而 HTTP/2 通过 Stream 这一设计,允许请求并发传输。因此,HTTP/1.1 时代 Chrome 通过 6 个连接访问页面的速度,远远比不上 HTTP/2 单连接的速度
为了理解 HTTP/2 的并发是怎样实现的,你需要了解 Stream、Message、Frame 这 3 个概念。
Message&Frame
HTTP 请求和响应都被称为 Message 消息,它由 HTTP 头部和包体构成,承载这二者的叫做 Frame 帧,它是 HTTP/2 中的最小实体。Frame 的长度是受限的,比如 Nginx 中默认限制为 8K(http2_chunk_size 配置),因此我们可以得出 2 个结论:HTTP 消息可以由多个 Frame 构成,以及 1 个 Frame 可以由多个 TCP 报文构成(TCP MSS 通常小于 1.5K)。
Stream
再来看 Stream 流,它与 HTTP/1.1 中的 TCP 连接非常相似,当 Stream 作为短连接时,传输完一个请求和响应后就会关闭;当它作为长连接存在时,多个请求之间必须串行传输。在 HTTP/2 连接上,理论上可以同时运行无数个 Stream,这就是 HTTP/2 的多路复用能力,它通过 Stream 实现了请求的并发传输。
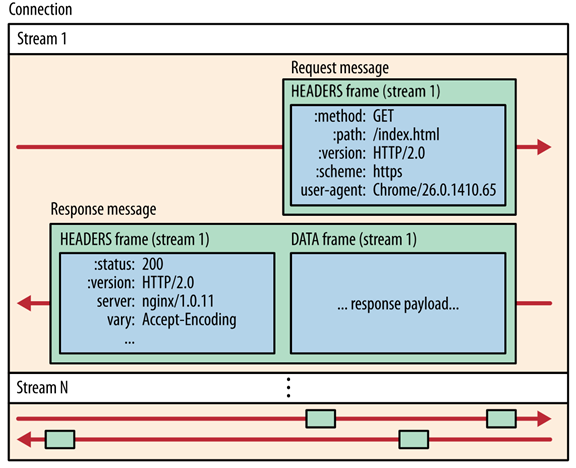
虽然 RFC 规范并没有限制并发 Stream 的数量,但服务器通常都会作出限制,比如 Nginx 就默认限制并发 Stream 为 128 个(http2_max_concurrent_streams 配置),以防止并发 Stream 消耗过多的内存,影响了服务器处理其他连接的能力。
HTTP/2 的并发性能比 HTTP/1.1 通过 TCP 连接实现并发要高。这是因为,当 HTTP/2 实现 100 个并发 Stream 时,只经历 1 次 TCP 握手、1 次 TCP 慢启动以及 1 次 TLS 握手,但 100 个 TCP 连接会把上述 3 个过程都放大 100 倍!
服务器主动推送资源
HTTP/1.1 不支持服务器主动推送消息,因此当客户端需要获取通知时,只能通过定时器不断地拉取消息。HTTP/2 的消息推送结束了无效率的定时拉取,节约了大量带宽和服务器资源。
实现
首先,所有客户端发起的请求,必须使用单号 Stream 承载;其次,所有服务器进行的推送,必须使用双号 Stream 承载;最后,服务器推送消息时,会通过 PUSH_PROMISE 帧传输 HTTP 头部,并通过 Promised Stream ID 告知客户端,接下来会在哪个双号 Stream 中发送包体。
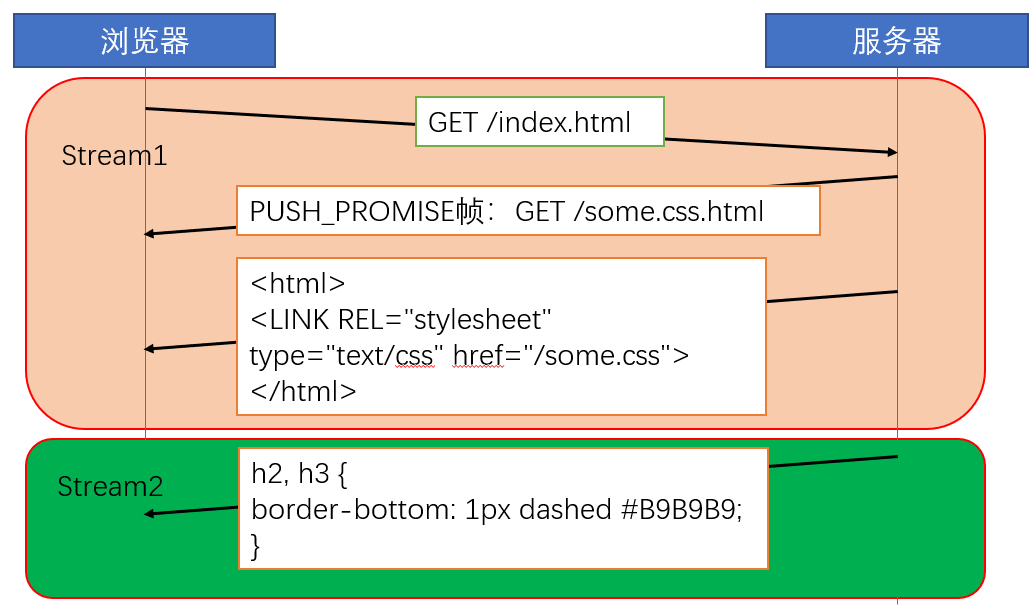
在 SDK 中调用相应的 API 即可推送消息,而在 Web 资源服务器中可以通过配置文件做简单的资源推送。比如在 Nginx 中,如果你希望客户端访问 /a.js 时,服务器直接推送 /b.js,那么可以这么配置:
location /a.js {
http2_push /b.js;
}
服务器同样也会控制并发推送的 Stream 数量(如 http2_max_concurrent_pushes 配置),以减少动态表对内存的占用。
虽然 HTTP/2.0 协议并没声明一定要用 SSL,但是 Google Chrome 等浏览器强制要求使用 HTTP/2.0 必须要用上 SSL, 也就是说必须要: https://; 但是如果是服务端微服务间调用,则可不使用https,即不配置证书