es用途
略
ES与DB的关系
ES:indices --> types --> documents --> fields
DB:databases --> tables --> rows --> columns
es的端口介绍
es端口分别为9200,9300;以下均基于9200端口介绍
* 9200: http协议的RESTful接口
* 9300:tcp通讯端口,集群间和TCPClient的通讯方式
es restful操作方式
POST /uri 创建
DELETE /uri/xxx 删除
PUT /uri/xxx 更新或创建
GET /uri/xxx 查看
POST不用加具体的id,它是作用在一个集合资源之上的(/uri),而PUT操作是作用在一个具体资源之上的(/uri/xxx)。
在ES中,如果不确定document的ID(documents具体含义见下),那么直接POST对应uri( “POST /website/blog” ),ES可以自己生成不会发生碰撞的UUID;
如果确定document的ID,比如 “PUT /website/blog/123”,那么执行创建或修改(修改时_version版本号提高1)
es镜像搭建
- 下载镜像
docker pull harbor.kanche.com/kanche/es-ik:2.3.5 - 启动镜像
docker run -d --name es-node -p 9201:9200 -p 9301:9300 5386bd3e3e68 -Des.cluster.name=b2c-test -Des.network.host=0.0.0.0 -Des.network.publish_host=0.0.0.0
es操作
查看es
添加索引
- 自动生成id
curl -X POST http://localhost:9000/student/base -d '{"name":"tom","age":23,"mobile":"13112345679"}'
- 手动指定id
curl -X POST http://localhost:9000/student/base/1 -d '{"name":"tom","age":23,"mobile":"13112345679"}'
- 以文件批量新增
curl -XPOST 'http://localhost:9000/student/base/_bulk?pretty' --data-binary "@es_tmp.json"
es_tmp.json内容格式:
{"index":{"_id":"1"}}
{"name":"tom","age":28,"mobile":"18654356728"}
{"index":{"_id":"2"}}
{"name":"tom","age":28,"mobile":"18654356728"}
- 以参数的形式批量新增(格式严格遵守下列格式,如最后一个单引号必须重启一行)
curl -XPOST http://localhost:9000/student/base/_bulk?pretty -d '
{"index":{"_id":"5"}}
{"name": "John Doe5" }
{"index":{"_id":"6"}}
{"name": "Jane Doe6" }
'
更新索引
- 修改数据,存在即修改,不存在即新增
curl -X PUT http://localhost:9000/student/base/AWUmz3KN1VWkjXAxlH-c -d '{"name":"admin","age":23,"mobile":"18513245321"}'
- 更新数据字段值
curl -XPOST 'http://localhost:9000/student/base/AWUmz3KN1VWkjXAxlH-c/_update?pretty' -d ' {
"doc": {
"name": "刘凯",
"mobile": "18511536230"
}
}'
- 批量更新
curl -XPOST http://localhost:9000/student/base/_bulk?pretty -d '
{"update":{"_id":"6"}}
{"doc": { "name": "John Doe becomes Jane Doe" } }
{"update":{"_id":"5"}}
{"doc": { "name": "John Doe becomes Jane Doe" } }
{"delete":{"_id":"1"}}
'
注:update及delete指定的只能是_id
删除索引
- 按id删除
curl -X DELETE http://localhost:9000/student/base/AWUm1Z1z1VWkjXAxlH-j
- 删除整个库
curl -XDELETE http://localhost:9200/student
- 删除索引库中的某类型数据
curl -XDELETE http://localhost:9200/student/base
- 按搜索结果删除
curl -XDELETE http://localhost:9200/student/base/_query?pretty -d '{"query":{"match":{"name":"keivn"}}}'
查询索引
- 按id查询
通过_source返回特定的字段,对于/index/base/id不起作用
curl http://localhost:9200/student/base/_search?pretty -d '{"_source":["name"]}'
- 按条件查询
curl http://localhost:9200/student/base/_search?pretty -d '{"query":{"match":{"name":"kevin"}}}'
- and
curl http://localhost:9200/student/base/_search?pretty -d '{"query":{"bool":{"must":[{"match":{"name":"kevin"}},{"match":{"age":"23"}}]}}}'
- or
curl http://localhost:9200/student/base/_search?pretty -d '{"query":{"bool":{"should":[{"match":{"name":"kevin"}},{"match":{"name":"tom"}}]}}}'
- 嵌套查询
curl -XPOST http://127.0.0.1:9200/student/base/_search?pretty -d '{"query": {"bool": {"must": [{ "match": { "name": "kevin" } }],"must_not": [{ "match": { "age": "23" }}]}}}'
- 模糊查询
设置字段mapping的分词器 为ik_smart
查询analyzer_field字段包含kevin或 tom的数据
curl http://localhost:9200/student/base/_search?pretty -d '{"query": { "match": { "analyzer_field": "kevin tom" } }}'
查询analyzer_field字段包含 kevin tom的数据
curl http://localhost:9200/student/base/_search?pretty -d '{"query": { "match_phrase": { "analyzer_field": "kevin tom" } }}'
- 分页与排序
以name字段排序,从坐标为2的数据开始查询(即第三条数据),查询3条数据,
curl -XPOST http://localhost:9200/student/base/_search?pretty -d '{"size":3,"from":2,"sort":[{"name":"asc"}]}'
- _all查询
查询符合kevin或 23的索引数据
curl 'localhost:9200/student/base/_search?q=kevin%2023&pretty'
创建索引
- 创建索引,自动生成mapping及setting
curl -XPUT 'localhost:9200/customer?pretty'
注:添加数据时,可自动创建索引,通过该方式创建的索引同样不能设置_settings,因为索引已存在
- 创建索引,手动指定mapping及setting
curl -XPOST http://localhost:9200/test1 -d '{"settings" : {"number_of_shards":8,"number_of_replicas" : 1,"refresh_interval":"30s"},"mappings":{"test_type":{"properties":{"name":{"type":"string"}}}}}'
查看分词效果
curl -X GET "http://localhost:9000/test/_analyze?analyzer=standard&pretty=true" -d "i am a cool boy keivn"
curl -X GET "http://localhost:9000/test/_analyze?analyzer=ik_smart&pretty=true" -d "我是一个IT工程师"
更新mapping
curl -XPOST "http://127.0.0.1:9200/student/base/_mapping?pretty" -d '{
"base": {
"properties": {
"analyzer_field":{
"type":"string",
"analyzer":"ik_smart"
}
}
}
}'
Elasticsearch的mapping一旦创建,只能增加字段,而不能修改已经mapping的字段.修改会提示“Mapper for [name] conflicts with existing mapping in other types:\n[mapper [name] has different [store] values]”
es表示字符串的两种类型
- keyword:直接创建索引
- text:先分词后创建索引,并且分词时,可指定分词器,如ik
别名
- 设置别名
curl -XPOST 'http://localhost:9200/_aliases' -d '{"actions" : [{ "add" : { "index" : "test1","alias" : "t" } } ] }' - 查看别名
curl -XGET http://10.3.1.15:9200/vehicleb/_alias/*
curl -XGET '10.3.1.15:9200/_alias/v'
查看配置
- 查看所有索引的配置
curl http://localhost:9000/_all/_settings?pretty - 查看某索引的配置
curl http://localhost:9000/student/_settings?pretty - 修改某索引的配置
number_of_shareds 分片数
number_of_replicas 副本数
refresh_interval 数据缓冲区刷新时间
curl -XPUT http://localhost:9000/student2?pretty -d'
{
"settings" : {
"number_of_shards":8,
"number_of_replicas" : 1,
"refresh_interval":"30s"
}
}'
其它查询
- 查询集群是否健康
curl 'localhost:9200/_cat/health?v' - 获取集群的节点列表
curl 'localhost:9200/_cat/nodes?v' - 列出所有索引
curl 'localhost:9200/_cat/indices?v'
分片与副本
-
分片介绍
分布式存储系统为了解决单机容量以及容灾的问题,都需要有分片以及副本机制。Elasticsearch 没有采用节点级别的主从复制,而是基于分片。它当前还未提供分片切分(shard-splitting)的机制,只能创建索引的时候静态设置。 -
分片算法
shard = hash(routing) % number_of_primary_shards
routing值是一个任意字符串,它默认是_id但也可以自定义,这个routing字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远是0到number_of_primary_shards - 1,这个数字就是特定文档所在的分片。
当索引已经存在时,不允许重新调整分片,只有将索引删除后(非删除数据,而是删除索引库),才能设置分片
- Elasticsearch 禁止同一个分片的主分片和副本分片在同一个节点上,即副本数不得大于节点数
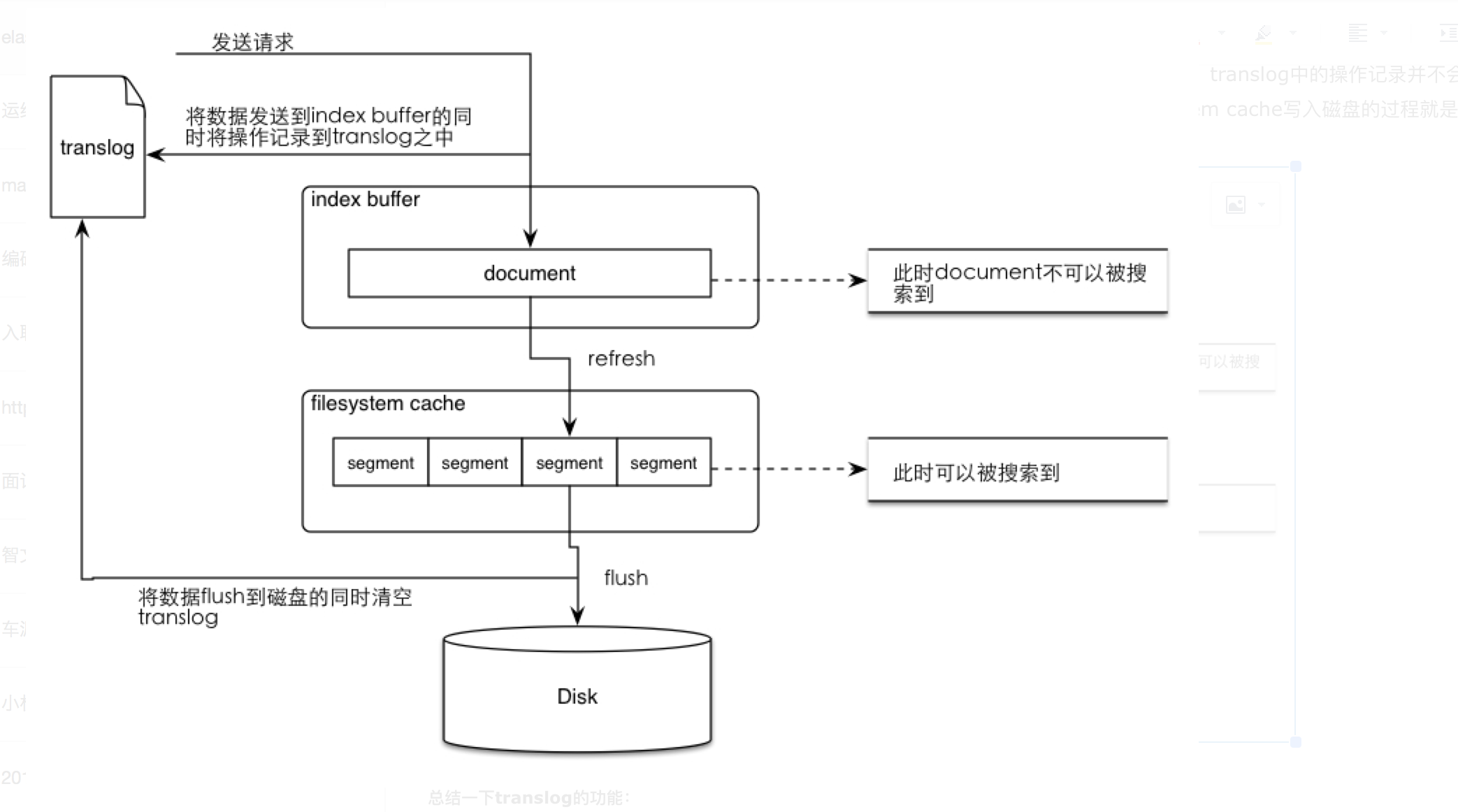
es数据的存储过程
es集群
discovery.zen.ping.unicast.hosts是集群中的节点信息,可以使用IP地址、可以使用主机名(必须可以解析)。
vim /etc/elasticsearch.yml
cluster.name: aubin-cluster # 集群名称
node.name: els1 # 节点名称,仅仅是描述名称,用于在日志中区分
path.data: /var/lib/elasticsearch # 数据的默认存放路径
path.logs: /var/log/elasticsearch # 日志的默认存放路径
network.host: 0.0.0.0
* 当前节点的IP地址
http.port: 9200 # 对外提供服务的端口,9300为集群服务的端口
discovery.zen.ping.unicast.hosts: ["172.18.68.11", "172.18.68.12","172.18.68.13"]
# 集群个节点IP地址,也可以使用els、els.shuaiguoxia.com等名称,需要各节点能够解析
discovery.zen.minimum_master_nodes: 2 # 为了避免脑裂,集群节点数最少为 半数+1
es的分布式
- 所有创建索引和类型的请求都会请求到master节点
- 而数据的写入会根据routing规则,route到集群中的任意节点,所以数据写入压力是分散到整个集群的
问题
index_closed_exception
{"error":{"root_cause":[{"type":"index_closed_exception","reason":"closed","index_uuid":"0WXuEc1aT1quPepsO5e0nQ","index":"message"}],"type":"index_closed_exception","reason":"closed","index_uuid":"0WXuEc1aT1quPepsO5e0nQ","index":"message"},"status":400}
因为index被关闭了,使用curl -i -XPOST 'http://localhost:9200/megacorp/_open/?pretty'命令可以在打开。通过curl localhost:9200/_cat/indices可以查看开启关闭的状态
其它问题
一万条限制
文档大小限制