- k8s基本概念
namespace
-
概念
- 资源隔离的一种手段
- 不同NS中的资源不能相互访问
- 多租户的一种常见解决方案
-
操作
[root@test-master1 yaml]# kubectl get namespaces
NAME STATUS AGE
default Active 1d
kube-system Active 1d
node
- 概念
- 一个Linux主机
- K8s中的工作节点(负载节点)
- 启动和管理K8s中的Pod实例
- 接受Master节点的管理指令
- 具有一定的自修复能力
- master节点
- K8s集群的管理节点
- 负责集群的管理
- 提供集群的资源数据访问入口
- 操作
- 获取节点
[root@test-master1 yaml]# kubectl get nodes NAME STATUS AGE test-master1 NotReady 1d test-node1 Ready 1d test-node2 Ready 1d
- 获取节点
resources
-
概念
- 集群中的一种资源对象
- 处于某个命名空间中
- 可以持久化存储到Etcd中
- 资源是有状态
- 资源是可以关联的
- 资源是可以限定使用配额
默认情况下,Kubernetes中所有容器都没有任何CPU和内存限制。LimitRange用来给Namespace增加一个资源限制,包括最小、最大和默认资源
-
操作
-
创建资源
apiVersion: v1 kind: LimitRange metadata: name: mylimits spec: limits: - max: cpu: "2" memory: 1Gi min: cpu: 200m memory: 6Mi type: Pod - default: cpu: 300m memory: 200Mi defaultRequest: cpu: 200m memory: 100Mi max: cpu: "2" memory: 1Gi min: cpu: 100m memory: 3Mi type: Container -
获取资源
[root@test-master1 yaml]# kubectl get limits No resources found.
-
pod
- 概念
- 一组容器的一个“单一集合体”,即一个pod中可以有多个容器
- K8s中的最小任务调度单元
- 可以被调度到任意Node上恢复
- 一个Pod里的所有容器共享资源(网络、Volumes)
- 每次在pod启动时,都会向其它的pod中注入该pod的clust_ip及端口等环境变量;通过env命令可查看
Replication Controller
-
概念:保证了在所有时间内,都有特定数量的Pod副本正在运行,如果太多了,Replication Controller就杀死几个,如果太少了,Replication Controller会新建几个,和直接创建的pod不同的是,Replication Controller会替换掉那些删除的或者被终止的pod,不管删除的原因是什么(维护阿,更新啊,Replication Controller都不关心)。基于这个理由,我们建议即使是只创建一个pod,我们也要使用Replication Controller。Replication Controller 就像一个进程管理器,监管着不同node上的多个pod,而不是单单监控一个node上的pod,Replication Controller 会委派本地容器来启动一些节点上服务(Kubelet ,Docker)。
-
常用的使用模式
- Rescheduling(重新规划):正如我们之前提到的,无论你是有1个或者有1000个pod需要运行,Replication Controller 会确保该数量的pod在运行,甚至在节点(node)失败或者节点(node)终止的情况下
- Scaling(缩放):Replication Controller让我们更容易的控制pod的副本的数量,不管我们是手动控制还是通过其它的自动管理的工具,最简单的:修改replicas的值
- Rolling updates(动态更新):Replication Controller 可以支持动态更新,当我们更新一个服务的时候,它可以允许我们一个一个的替换pod,这样就可以规避升级过程中出现的未知错误了;理论上,动态更新控制器应考虑应用的可用性,并确保足够的pod制成服务在任何时间都能正常提供服务;两个Replication Controller创建的pod至少要由一个不同的标签,可以是镜像的标签,因为一般镜像的更新都会带来一个新的更新;kubectl是实现动态更新的客户端
- Multiple release tracks(多个发布版本追踪):除了在程序更新过程中同时运行多个版本的程序外,在更新完成之后的一段时间内或者持续的同时运行多个版本(新旧),通过多国版本的追踪(版本的追踪是通过label来实现的)
举个例子来说:一个服务可能绑定的Pod为tier in (frontend), environment in (prod),现在我们旧假设我们由10个副本来组成这个tier,现在我们要发布一个新的版本canary,这个时候,我们就应该设置一个Replication Controller,并且设置replcas的值为9,并且标签为tier=frontend, environment=prod, track=stable,然后再设置另外一个Replication Controller,并且把replacas的值设置为1标签为:tier=frontend, environment=prod, track=canary.现在这个服务就同时使用了新版和旧版两个版本了,这个时候我们旧可以通过不同的Replication Controller进行一些测试,监控…
-
操作
service
- 概念:Kubernete Service 是一个定义了一组Pod的策略的抽象,我们也有时候叫做宏观服务。这些被服务标记的Pod都是(一般)通过label Selector决定的
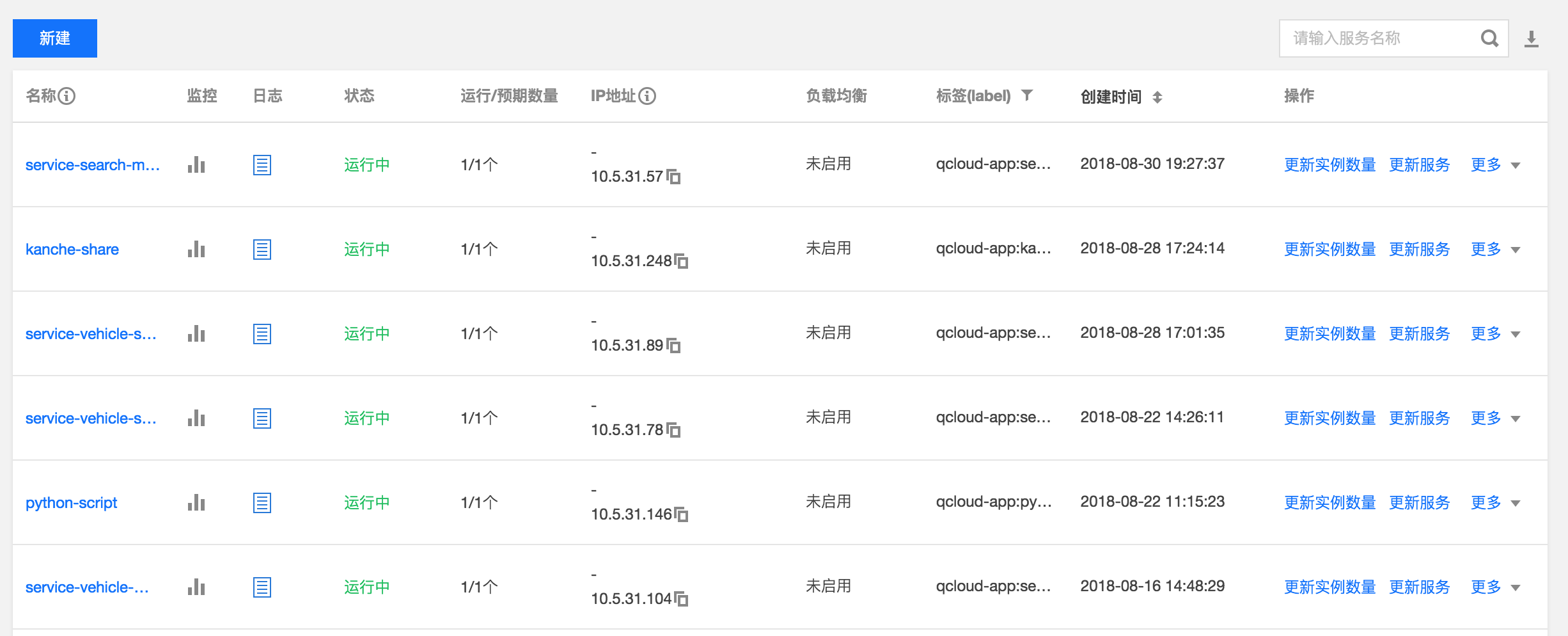
即,对一组pod提供一个对外的统一ip及服务,下图为腾讯云中的服务列表,每行为一个服务,每个服务中可以启动n个pod实例
srvice nodeport 类型
会随机在每个node上启动一个同样的端口,通过该端口可访问至服务
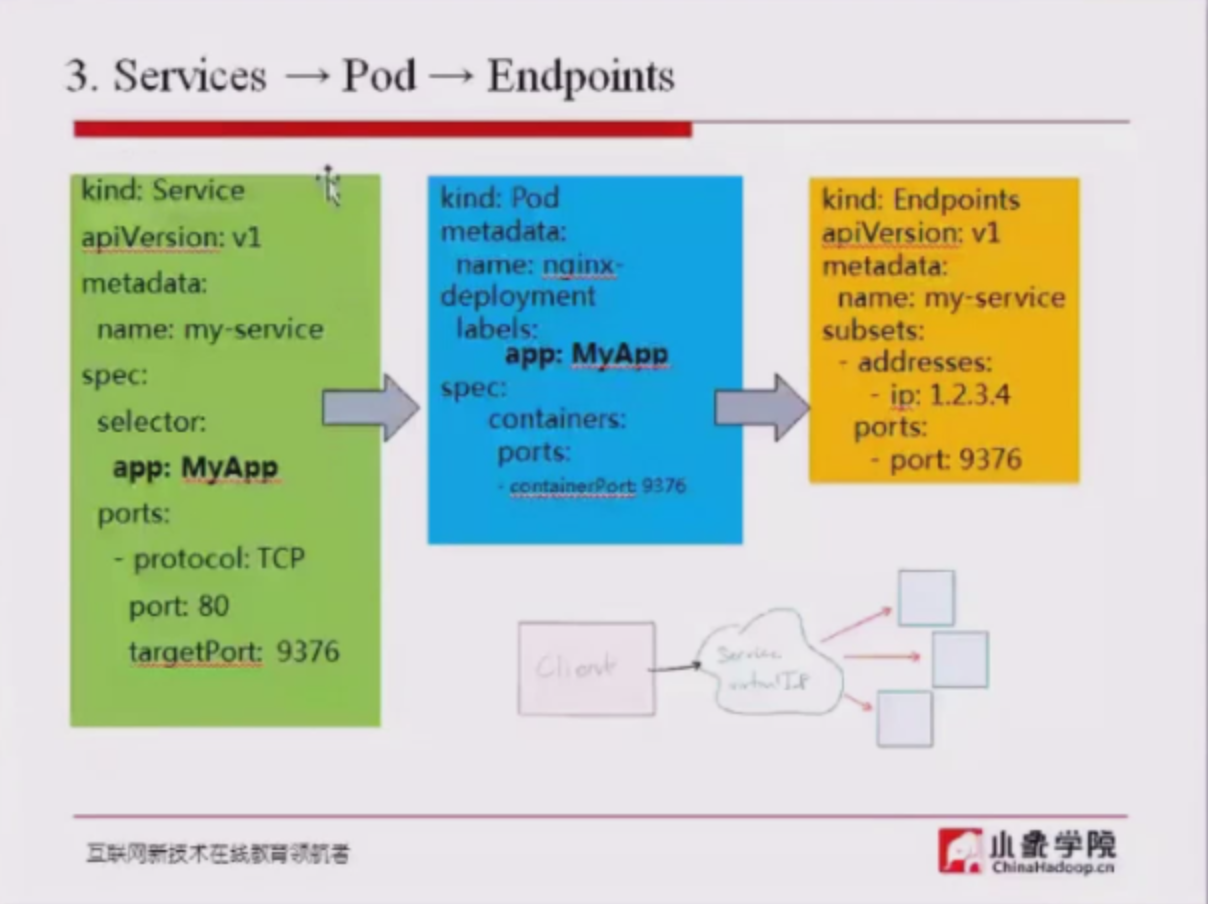
endpoint
- 如果不存在service对应label的pod,则可通过修改endpoint中的值达到负载的效果
- 每个service对应一个endpoint,该endpoint中会列出所有该service对应的pod的ip

Deployment
- 概念: Deployment为Pod和ReplicaSet提供了一个声明式定义(declarative)方法,用来替代以前的ReplicationController来方便的管理应用,在deployment变更时,会创建一个新的rs,直到新的rs启动完成,则将之前的rs删除。典型的应用场景包括:
- 定义Deployment来创建Pod和ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续Deployment
比如一个简单的nginx应用可以定义为
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
扩容:
kubectl scale deployment nginx-deployment --replicas 10
如果集群支持 horizontal pod autoscaling 的话,还可以为Deployment设置自动扩展:
kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80
更新镜像也比较简单:
kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
回滚:
kubectl rollout undo deployment/nginx-deployment
ReplicaSets
- 概念:ReplicaSet是下一代复本控制器。ReplicaSet和 Replication Controller之间的唯一区别是现在的选择器支持。Replication Controller只支持基于等式的selector(env=dev或environment!=qa),但ReplicaSet还支持新的,基于集合的selector(version in (v1.0, v2.0)或env notin (dev, qa))。虽然ReplicaSets可以独立使用,但是今天它主要被 Deployments 作为协调pod创建,删除和更新的机制。当您使用Deployments时,您不必担心管理他们创建的ReplicaSets。Deployments拥有并管理其ReplicaSets。
Labels
- 概念:标签其实就一对 key/value ,被关联到对象上,比如Pod,标签的使用我们倾向于能够标示对象的特殊特点,并且对用户而言是有意义的(就是一眼就看出了这个Pod是尼玛数据库),但是标签对内核系统是没有直接意义的。标签可以用来划分特定组的对象(比如,所有女的),标签可以在创建一个对象的时候直接给与,也可以在后期随时修改,每一个对象可以拥有多个标签,但是,key值必须是唯一的
Ingress
通常情况下,service和pod的IP仅可在集群内部访问。集群外部的请求需要通过负载均衡转发到service在Node上暴露的NodePort上,然后再由kube-proxy将其转发给相关的Pod。
而Ingress就是为进入集群的请求提供路由规则的集合,如下图所示
internet
|
[ Ingress ]
--|-----|--
[ Services ]
Ingress可以给service提供集群外部访问的URL、负载均衡、SSL终止、HTTP路由等。为了配置这些Ingress规则,集群管理员需要部署一个Ingress controller,它监听Ingress和service的变化,并根据规则配置负载均衡并提供访问入口。
- Ingress格式
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
spec:
rules:
- http:
paths:
- path: /testpath
backend:
serviceName: test
servicePort: 80
每个Ingress都需要配置rules,目前Kubernetes仅支持http规则。上面的示例表示请求/testpath时转发到服务test的80端口。
根据Ingress Spec配置的不同,Ingress可以分为以下几种类型:
- 单服务Ingress
单服务Ingress即该Ingress仅指定一个没有任何规则的后端服务。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
spec:
backend:
serviceName: testsvc
servicePort: 80
注:单个服务还可以通过设置Service.Type=NodePort或者Service.Type=LoadBalancer来对外暴露。
- 路由到多服务的Ingress
路由到多服务的Ingress即根据请求路径的不同转发到不同的后端服务上,比如
foo.bar.com -> 178.91.123.132 -> / foo s1:80
/ bar s2:80
可以通过下面的Ingress来定义:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
backend:
serviceName: s1
servicePort: 80
- path: /bar
backend:
serviceName: s2
servicePort: 80
使用kubectl create -f创建完ingress后:
$ kubectl get ing
NAME RULE BACKEND ADDRESS
test -
foo.bar.com
/foo s1:80
/bar s2:80
- 虚拟主机Ingress
虚拟主机Ingress即根据名字的不同转发到不同的后端服务上,而他们共用同一个的IP地址,如下所示

下面是一个基于Host header路由请求的Ingress:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test
spec:
rules:
- host: foo.bar.com
http:
paths:
- backend:
serviceName: s1
servicePort: 80
- host: bar.foo.com
http:
paths:
- backend:
serviceName: s2
servicePort: 80
注:没有定义规则的后端服务称为默认后端服务,可以用来方便的处理404页面。
- TLS Ingress
TLS Ingress通过Secret获取TLS私钥和证书(名为tls.crt和tls.key),来执行TLS终止。如果Ingress中的TLS配置部分指定了不同的主机,则它们将根据通过SNI TLS扩展指定的主机名(假如Ingress controller支持SNI)在多个相同端口上进行复用。
定义一个包含tls.crt和tls.key的secret:
apiVersion: v1
data:
tls.crt: base64 encoded cert
tls.key: base64 encoded key
kind: Secret
metadata:
name: testsecret
namespace: default
type: Opaque
Ingress中引用secret:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: no-rules-map
spec:
tls:
- secretName: testsecret
backend:
serviceName: s1
servicePort: 80
注意,不同Ingress controller支持的TLS功能不尽相同。 请参阅有关nginx,GCE或任何其他Ingress controller的文档,以了解TLS的支持情况。
- 更新Ingress
可以通过kubectl edit ing name的方法来更新ingress:
$ kubectl get ing
NAME RULE BACKEND ADDRESS
test - 178.91.123.132
foo.bar.com
/foo s1:80
$ kubectl edit ing test
这会弹出一个包含已有IngressSpec yaml文件的编辑器,修改并保存就会将其更新到kubernetes API server,进而触发Ingress Controller重新配置负载均衡:
spec:
rules:
- host: foo.bar.com
http:
paths:
- backend:
serviceName: s1
servicePort: 80
path: /foo
- host: bar.baz.com
http:
paths:
- backend:
serviceName: s2
servicePort: 80
path: /foo
..
更新后:
$ kubectl get ing
NAME RULE BACKEND ADDRESS
test - 178.91.123.132
foo.bar.com
/foo s1:80
bar.baz.com
/foo s2:80
当然,也可以通过kubectl replace -f new-ingress.yaml命令来更新,其中new-ingress.yaml是修改过的Ingress yaml。
job
创建执行某个任务的容器,执行结束后即停止
cronjob
- 创建在某时间点执行某任务的容器,执行结束后即停止
- 该定时任务实际为在某时刻启动一个job,由job启动一个pod执行任务
ConfigMap
ConfigMap API资源用来保存key-value pair配置数据,这个数据可以在pods里使用,或者被用来为像controller一样的系统组件存储配置数据。虽然ConfigMap跟Secrets类似,但是ConfigMap更方便的处理不含敏感信息的字符串。 注意:ConfigMaps不是属性配置文件的替代品。ConfigMaps只是作为多个properties文件的引用。你可以把它理解为Linux系统中的/etc目录,专门用来存储配置文件的目录ServiceAccount
k8s账号 可通过`kubectl get sa `查看,通过`kubectl create sa test-sa`创建账号,通过该账号可执行apisecret
k8s 账号证书及token
通过kubectl get secret可查看列表
role
k8s sa 配置的角色
通过kubectl get role可查看列表
rolebinding
kubectl create rolebinding my-sa-view \
--clusterrole=view \
--serviceaccount=my-namespace:my-sa \
--namespace=my-namespace
StatefulSet
StatefulSet是一个给Pod提供唯一标志的控制器,它可以保证部署和扩展的顺序。
当应用有以下任意要求时,StatefulSet的价值就体现出来了。
- 稳定的、唯一的网络标识。
- 稳定的、持久化的存储。
- 有序的、优雅的部署和扩展。
- 有序的、优雅的删除和停止