一. 结构图
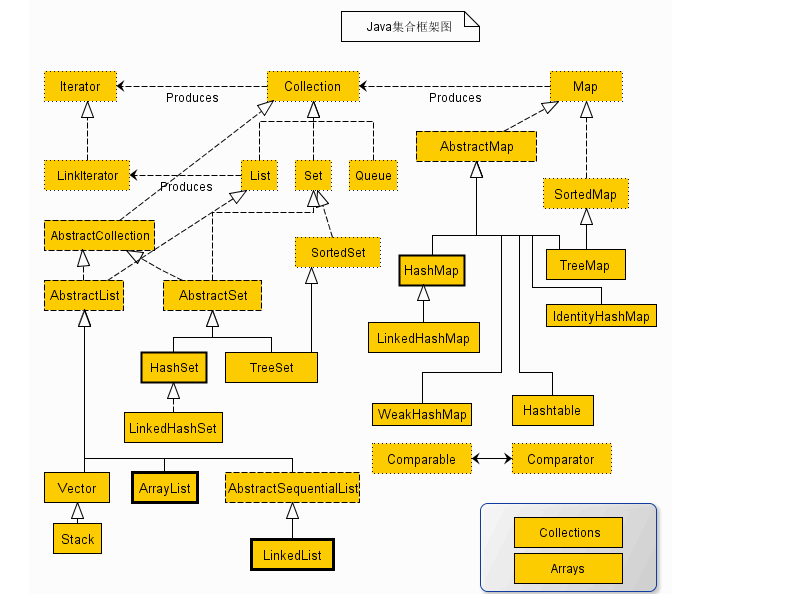
- Produces表示
二. Collection详解
1. 集合基本接口
-
Collection
通过上图可观察出Collection为所有集合的根接口,实际该接口仍然继承了一个接口Iterable,Iterable定义了创建迭代器(Iterator)的方法,因此所有集合(map接口并没有继承Collection接口)均可创建迭代器对象(详见迭代器设计模式)。该接口定义了一系列集合的基本公用方法如size(),add(),remove()等。 -
Iterator
迭代器接口,包含了hasNext(),next(),remove()三个方法,对数据存储对象(即集合)进行遍历,移除,使用迭代器可以在不关心数据存储细节的情况下,对存储数据进行遍历,比如抽象类AbstractList中并未定义数据如何存储,但是却通过迭代器的方式实现了remove等方法 -
ListIterator(上图中的LinkIterator是错误的)
继承了Iterator接口,Iterator的定位是所有的java数据对象的迭代器对象,ListIterator继承了Iterator对象,通过名字就可以知道ListIterator为集合的迭代器对象,在Iterator的基础上又新增了一些针对List类集合的方法如previous(),nextIndex(),previousIndex()等,针对List类集合添加这些方法的原因是list是有序的,而set是无序的,但是需要注意的是ListIterator并不是通过iterator方法返回的,换句话说就是List并没有重写Iterable的itreator方法返回ListIterator,而是新增了一个listIterator()方法返回ListIterator对象(原因不明)。 -
List Set Queue
List相比Set,最大的区别是set中不允许保存重复对象,而List可以保存重复对象,另外List比Set中多了一些通过index操作数据的方法,因为List是有序的,而Set是无序的(不按存储顺序排序)。而Queue是队列,包含了方法poll()【移除并返问队列头部的元素】,peek()【返回队列头部的元素】等方法。如果仔细的话会发现Collection中已经声明了add方法,但是List Set Queue继承了Collection,但是又声明了一遍完全一样的add方法,感觉这完全是无必要的,查询很多资料后总结为:其实只是定义的接口行为不一样。表示子类如果实现List接口,那就需要遵循List Javadoc的行为。如果实现Collection那就必须要遵循Collection Javadoc的行为。不单单只是重写一个方法而已,重写这个方法的时候应该按照Javadoc所描述的一样。这样才正确。 -
AbstractCollection,AbstractList,AbstractSet
Collection,List,Set接口均存在一个与之对应的抽象类AbstractCollection,AbstractList,AbstractSet。由于List,Set继承了接口Collection,而AbstractList是List的实现,所以AbstractList在继承AbstractCollection的同时实现了接口List
2. set具体实现类
HashSet TreeSet LinkedHashSet
- TreeSet: 目前jdk中唯一的SortedSet接口实现类,有序的set集合,正常感觉set都是无序不可重复的,TreeSet为有序的,是不是与set的定义冲突了呢,其实set也是有序的,包括hashset对象,只不过set的有序与list不同,list是按存储的顺序保存而set并不是按存储的顺序保存(所以总是被误解为无序),如hashset是通过对象的hashcode排序存储,而treeset默认是按照元素的自然顺序排序,也可以通过指定比较器(Comparator)的方式,使数据按照特定的顺序排序。实际存储使用的是TreeMap
- HashSet: 平时用的最多,通过对象的hash码顺序保存数据。实际存储使用的是HashMap
- LinkedHashSet: LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起 来像是以插入顺序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet。实际存储使用的是LinkedHashMap
所以了解HashSet TreeSet LinkedHashSet前需要先了解Treemap Hashmap LinkedHashMap
3. list具体实现类
ArrayList与LinkedList
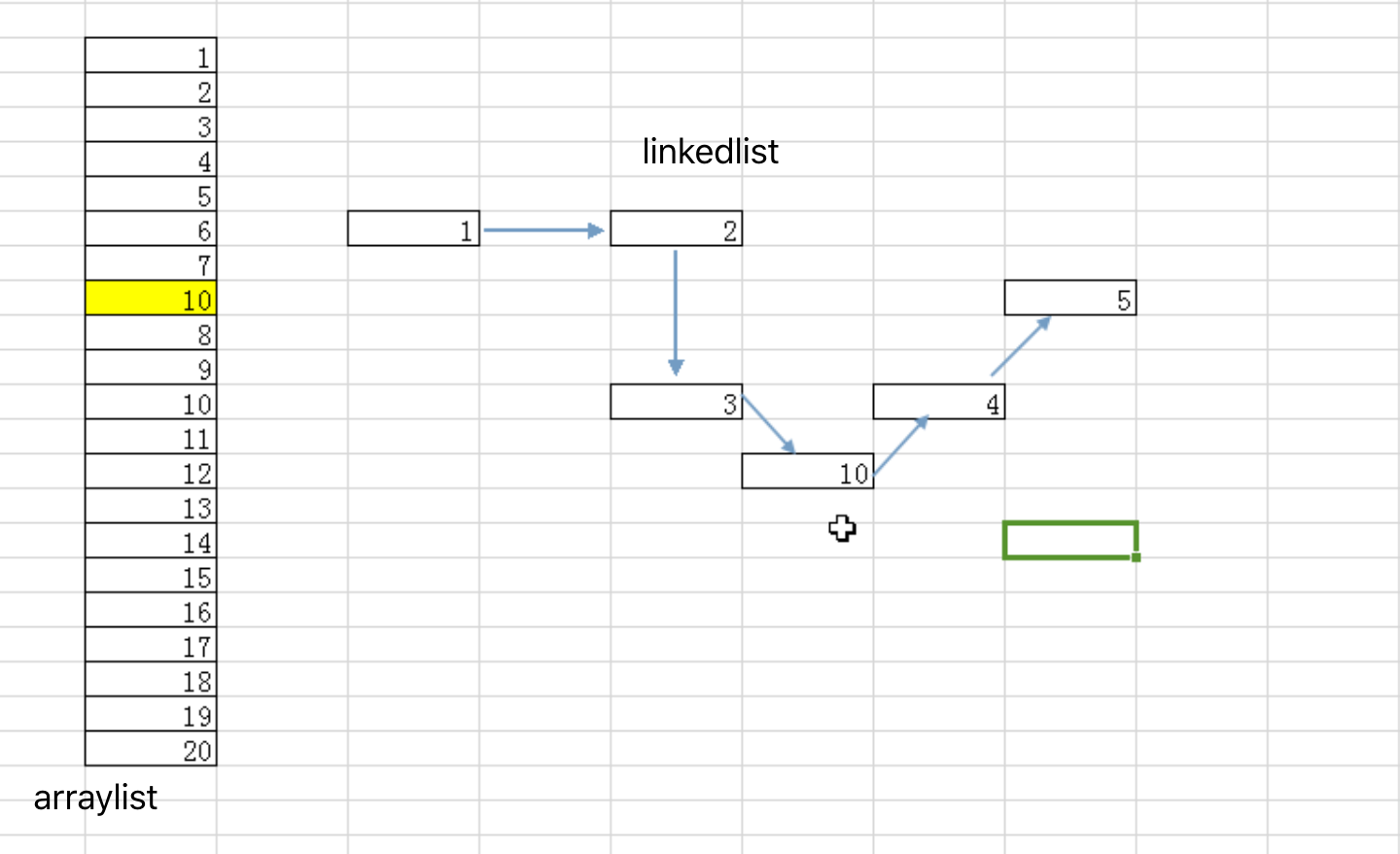
上图完美的说明了arraylist与linkedlist的存储结构
- ArrayList 是一个可改变大小的数组.当更多的元素加入到ArrayList中时,其大小将会动态地增长.内部的元素可以直接通过get与set方法进行访问,因为ArrayList本质上就是一个数组.
- arraylist 存储地址是连续的,linkedlist的存储地址不是连续的;而是通过上一个的指向找到下一个数据,所以LinkedList间接实现了queue接口,因为LinkedList比较适合做队列
- arraylist如果要插入数据,需要将所有欲插入之后 的数据移动 ;而 LinkedList 是一个双链表只需要修改指向,在添加和删除元素时具有比ArrayList更好的性能.但在get与set方面弱于ArrayList.
- 当然,这些对比都是指数据量很大或者操作很频繁的情况下的对比,如果数据和运算量很小,那么对比将失去意义
linkedList的get(int index)方法:
Entry<E> e = header;
if (index < (size >> 1)) {
for (int i = 0; i <= index; i++)
e = e.next;
} else {
for (int i = size; i > index; i--)
e = e.previous;
}
ArrayList与Vector


- Vector和ArrayList几乎是完全相同的,唯一的区别在于Vector是同步类(synchronized).因此,开销就比ArrayList要大.正常情况下,大多数的Java程序员使用ArrayList而不是Vector,因为同步完全可以由程序员自己来控制。
- Vector和ArrayList在更多元素添加进来时会请求更大的空间。Vector每次请求其大小的双倍空间,而ArrayList每次对size增长50%.
注意: 默认情况下ArrayList的初始容量非常小,所以如果可以预估数据量的话,分配一个较大的初始值属于最佳实践,这样可以减少调整大小的开销。
三. Map详解
1. Map基础接口及抽象类
- Map
将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。该接口定义了一系列对键值对的操作方法,如get(Object),put(K,V)等。
Set<Map.Entry<K, V>> entrySet() 该方法返回一个实体set集合对象,该set对象由各个Map实体中创建一个继承于AbstractSet的Set对象,之所以没有在各实体类中使用hashSet等现有set的原因是,现有每个set的实体类都有该类自己的迭代器实现,但是不同map中的entryset实现均不同,比如 size直接返回map的size,而不需要重新计算;另外包括 contains及remove在不同的map实现类中方法实现均不同,并且与map.entry深度耦合 - AbstractMap
通过迭代器的方式实现了Map中的部分方法,如get方法,先取到实体的Set信息,然后循环判断key是否相等,相等则返回 - SortedMap
有序的map接口,它的接口应该支持默认的自然排序及通过指定的比较器排序
2. Map实现类详解
TreeMap
(引用自http://blog.csdn.net/jzhf2012/article/details/8540705)
- 实现了接口SortedMap,所以TreeMap是一个key有序的数据存储对象
- TreeMap基于红黑树实现,所有每个Entry存在一个父Entry
- 通过TreeMap的Entry类可以看到,实体中存在left和right实体对象,指定他的左右节点
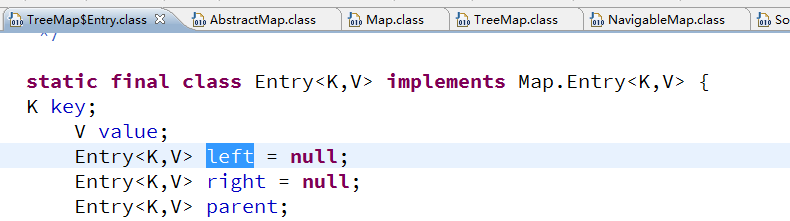
- put时,先判断是否存在root,若不存在则直接建为root节点,若存在则将当前节点与root比较,若小于当前节点,则再与root的左节点比较,若大于当前节点,则与root的右节点比较,直到某节点不存在左或右节点,将该节点放在该位置
- 在put(K key,V value)方法的末尾调用了fixAfterInsertion(Entry<K,V> x)方法,这个方法负责在插入节点后调整树结构和着色,以满足红黑树的要求。(红黑树不详细说,了解以树形结构存储即可)
- 每一个节点或者着成红色,或者着成黑色。
- 根是黑色的。
- 如果一个节点是红色的,那么它的子节点必须是黑色的。
- 一个节点到一个null引用的每一条路径必须包含相同数量的黑色节点。
HashMap
- HashMap使用数组和链表两种数据存储形式存储数据
- 当get数据时,先根据key计算出该数据的数组坐标,若数据位置上存在对象,则使用==及.equal的方式判等,若相等则返回,不等则取到下一个对象判等,若数据该坐标的链状结构不存在相与入参相等的key,则返回null.
- 当put数据时,先根据key计算出该数据的数组坐标,若当前位置为不存在数据,则直接插入,若当前位置存在数据,则使用链表结构将欲插入的数据插入数组的当前坐标位置上,并将之前的数据保存到新的entry的next上
- HashMap中存在HashIterator,KeyIterator,ValueIterator,EntryIterator等四个Iterator对象,其中HashIterator为抽象类,其它三个对象均继承HashIterator抽象类,并实现next方法,在三个实现类中均调用nextNode()方法,不同的是EntryIterator的next为nextNode(),KeyIterator为nextNode().key,ValueIterator为nextNode().value,因此hashmap的迭代重点在HashIterator的nextNode方法上
- 通过下述代码可看出nextNode是先取该对象的next对象,若查询到为null,则查询数据t的下一个index是否为空,直至不为空则返回该对象
Node<K,V> e = next;
if ((next = (current = e).next) == null && (t = table) != null) {
do {
} while (index < t.length && (next = t[index++]) == null);
}
- HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个index的链就会很长,会不会影响性能?HashMap里面设置一个因子,随着map的size越来越大,Entry[]会以一定的规则加长长度。
- HashMap不同jdk实现代码有较大区别,重要的是理解逻辑!!!下面的示例为jdk1.6!!!
public V put(K key, V value) {
// HashMap允许存放null键和null值。
// 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
if (key == null)
return putForNullKey(value);
// 根据key的keyCode重新计算hash值。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//循环遍历map,判断当前key在map中是否已存在
//如果已存在,则替换old值 ,并返回old值
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//HashMap的结构被修改的次数
modCount++;
addEntry(hash, key, value, i);
return null;
}
/*http://www.th7.cn/Program/java/201511/689291.shtml
先复习一下逻辑与,0 & 0 = 0;0 & 1 = 0;1 & 0 = 0;1 & 1 = 1。
第二个参数length始终为2的n次方,所以,换成二进制数就是 100,1000,10000,...(length -1)就是 11, 111,1111,...
这样的话,第一个参数h比第二个参数小的情况下,那结果就是h。第一个参数h比第二个参数大的情况下,如下:
例:h=18 -> 10010 length-1=15 -> 01111 10010&01111-------00010 (即2)
也就是h-length,假设 h=5,length=16, 那么 h & length - 1 将得到 5;
如果 h=6,length=16, 那么 h & length - 1 将得到 6 ……
如果 h=15,length=16, 那么 h & length - 1 将得到 15;
但是当 h=16 时 , length=16 时,那么 h & length - 1 将得到 0 了;
当 h=17 时 , length=16 时,那么 h & length - 1 将得到 1 了这样就能保证取得合理的索引值。
*/
//获取坐标 HashMap存取时,都需要计算当前key应该对应Entry[]数组哪个元素,即计算数组下标
static int indexFor(int h, int length) {
return h & (length-1);
}
//添加实体,将当前实体插入到table[index]位置上,若之前该位置已存在entry,则将之前的entry,
//以最新的entry对象的next对象属性形式(链表形式)保存
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//如果当前的map size大于了下次的数组长度,则对map重新设置大小为现在的2倍,并对新的数组重新赋值
if (size++ >= threshold)
resize(2 * table.length);
}
Hashtable
与HashMap实现方式一样,但Hashtable属于同步(synchronized)的.


LinkedHashMap
(引用自http://wiki.jikexueyuan.com/project/java-collection/linkedhashmap.html此链接是对jdk6的解释,以下是对jdk8的解释,理解思想最重要)
- LinkedHashMap继承于类HashMap
- LinedHashMap可以通过插入顺序或访问顺序遍历对象
- LinkedHashMap 实现与 HashMap 的不同之处在于,LinkedHashMap 维护着一个运行于所有条目的双重链接列表(通过一个对象可查询该对象的before及after对象)。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
- 根据链表中元素的顺序可以分为:按插入顺序的链表,和按访问顺序(调用 get 方法)的链表。默认是按插入顺序排序,如果指定按访问顺序排序,那么调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。new LinkedHashMap<String, String>(16,0.75f,true); true表示按访问顺序,false表示按存储顺序
- LinkedHashMap get方法与HashMap的get方法一致,调用的是HashMap的getNode(hash(key), key),不同的是LinkedHashMap存在两种排序方式,若使用按访问顺序排序的话,在get方法中调用afterNodeAccess(e);将该对象移至尾部
- jdk8中对map做了一些优化,当节点个数>= TREEIFY_THRESHOLD - 1时,会将链表结构转化为红黑树结构存储。为什么这么做呢?正如我们前面提到的,当发生Hash冲突时,HashMap首先是采用链表将重复的值串起来,并将最后放入的值置于链首,java8对HashMap进行了优化。当节点个数多了之后使用红黑树存储。这样做的好处是,最坏的情况下即所有的key都Hash冲突,采用链表的话查找时间为O(n),而采用红黑树为O(logn),这也是Java8中HashMap性能提升的奥秘。
- 发现了一个有趣的事情,HashMap中存在一个static final class TreeNode,该类继承于LinkedHashMap.Entry,而LinkedHashMap.Entry继承于HashMap.Node,父类内部类继承子类内部类,为什么不在HashMap中创建LinkedHashMap.entry,LinedHashMap.Entry中直接使用该类,而要用父类的内部类实现子类的内部类,思想上没问题吗?
- LinkedHashMap 并未重写父类 HashMap 的 put 方法,而是重写了HashMap中调用的子方法,在HashMap中详细讲述了HashMap jdk1.6的put,在这里说一下HashMap jdk 1.8的put方法。(jdk1.6中重写了put方法中调用的子方法void recordAccess(HashMap m) ,void addEntry(int hash, K key, V value, int bucketIndex) 和void createEntry(int hash, K key, V value, int bucketIndex),提供了自己特有的双向链接列表的实现,但是在jdk1.8并不存在这几个方法)
- 在jdk8的put中直接调用putVal方法,在该方法中如果不存在该实体,则调用HashMap或LinkedHashMap各自的nextNode()方法创建实体对象,如果存在则修改,这里面主要有两个方法,第一就是nextNode()创建实体,不同的HashMap及其子类,创建的实体对象肯定不同,第二就是afterNodeAccess(),该方法是如果现在的数据有替换,则替换后调用该方法。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)//如果该坐标位置不存在对象,则直接创建
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))//判断当前坐标获取的对象key与入参key是否一致
e = p;
else if (p instanceof TreeNode)//如果p实例是TreeNode的实例,则调用putTreeValue方法,原因待研究
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//循环当前坐标的下一个实体,如果为null,则直接插入,如果不为null,则一直循环,直到为null或实体的key与入参key一致
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);//创建实体,并将最新的实体赋值给上一实体的next对象
//如果条件成立,将链表修改为红黑树结构,jdk8新的优化,所以在get和put时,都有校验 p instanceof TreeNode,这样查找效率从o(n)变成了o(log n)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))//判断实体的key与入参key是否相等
break;
p = e;
}
}
if (e != null) { // existing mapping for key map中已存在该实体
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);//HashMap的该方法是空方法,而LinkedHashMap的该方法,增加了在排序是访问顺序的情况下,对链表重新排序的操作
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
//HashMap的该方法为空方法,LinkedHashMap的该方法虽然不是空方法,但是实际并没有任务的意义,因为removeEldestEntry方法固定返回false
//这样做的目的是方便开发者可以把Map当cache来用,并且可以限制大小,只需继承LinkedHashMap并重写removeEldestEntry()
afterNodeInsertion(evict);
return null;
}
- LinkedHashMap 中同样存在四个迭代器LinkedHashIterator,LinkedKeyIterator,LinkedValueIterator,LinkedEntryIterator。其中LinkedHashIterator为抽象类,其它三个继承该类,与HashMap一致,不详述。
- 四个迭代器的精华为nextNode()方法,nextNode与Entry结合实现了顺序访问形式,以下为jdk8的代码,可见实现代码非常简单,一直获取after对象。但是通过代码可以发现如果直接调用nextNode(),而已经不存在下一个对象,则会抛出异常,所以在调用next()前一定先调用hasNext()方法
final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
}