目录
-
磁盘分区
- 磁盘分区概述
- linux磁盘设备文件
- 主分区、扩展分区与逻辑分区
- 分区大小
- Windows和Linux分区区别
-
分区机制
- MBR
- GPT
-
物理扇区及逻辑扇区
-
ext文件系统
- EXT2概述
- Superblock
- GDT(group descriptor table)
- inode bitmap
- block bitmap
- data block
- inode table
- ext4
- 目录是特殊的文件
-
journal日志
- journal block的创建
- journal挂载选项
-
参考
系统分区
磁盘分区概述
硬盘分区的存在,是由硬盘的物理特性决定的,并不会因为操作系统的不同而有所改变
但是分区并不是硬盘的物理功能,只是一种软件上的划分
硬盘分区有三种,主磁盘分区、扩展磁盘分区、逻辑分区。
一个硬盘主分区至少有1个,最多4个,扩展分区可以没有,最多1个。 且主分区+扩展分区总共不能超过4个。逻辑分区可以有若干个。
在windows下激活的主分区是硬盘的启动分区,他是独立的,也是硬盘的第一个分区,正常分的话就是C区。
在linux下主分区和逻辑分区都可以用来放系统,引导os开机,grub会兼容windows系统开机启动。 分出主分区后,其余的部分可以分成扩展分区,一般是剩下的部分全部分成扩展分区,也可以不全分,那剩的部分就浪费了。
但扩展分区是不能直接用的,他是以逻辑分区的方式来使用的,所以说扩展分区可分成若干逻辑分区。 他们的关系是包含的关系,所有的逻辑分区都是扩展分区的一部分。
- 硬盘的容量=主分区的容量+扩展分区的容量
- 扩展分区的容量=各个逻辑分区的容量之和
linux设备文件
在linux中第一块硬盘分区为hda分区(或者是sda分区),主分区编号为hda1-4,逻辑分区从5开始。
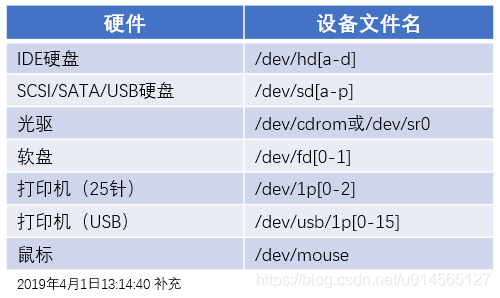
在Linux中,每一个设备都是用 /dev/ 文件夹下的一个文件来表示,如/dev/hda5前两位的字母 hd 表示这是一块IDE硬盘,如果是 sd ,则代表SATA硬盘,或者闪存等外设。第三位的字母 a 表示这是该类型接口上的第一个设备。同理, b、c、d…… 分别代表该类型接口上的第二三四……个设备。例如 hdc 表示第二个IDE接口上的主硬盘(每个IDE接口上允许一个主设备和一个从设备)。第四位的数字 5 ,并不表示这是该硬盘中的第5个分区,而是第一个逻辑分区。因为在Linux中,为了避免不必要的混乱,分区的顺序是不能改变的,分区标识则由它们在硬盘中的位置决定。系统又要为所有可能的主分区预留标识,所以 1-4 一定不会是逻辑分区, 5 则是第一个逻辑分区,以此类推。
主分区、扩展分区与逻辑分区
由于扩展分区只能有一个,所以这4个分区可以是4个主分区或者3个主分区加1个扩展分区,如下所示:
P + P + P + P
P + P + P + E
重点说明的是,扩展分区不能直接使用,还需要将其划分为逻辑分区才行.这样就产生了一个问题, 既然扩展分区不能直接使用,但为什么还要划分出一定的空间来给扩展分区呢?这是因为,如果用 户想要将硬盘划分为5个分区的话,那该如何?此时,就需要扩展分区来帮忙了.
MBR(主引导记录)的分区表(主分区表)只能存放4个分区,如果要分更多的分区的话就要 一个扩展分区表(EBR),扩展分区表放在一个系统ID为0x05的主分区上,这个主分区就是扩展分区, 扩展分区能可以分若干个分区,每个分区都是个逻辑分区
由于MBR仅能保存4个分区的数据信息,如果超过4个,系统允许在额外的硬盘空间存放另一份磁盘 分区信息,这就是扩展分区.若将硬盘分成3P+E,则E实际上是告诉系统,磁盘分区表在另外的那份 分区表,即扩展分区其实是指向正确的额外分区表.本身扩展分区不能直接使用,还需要额外将扩 展分区分成逻辑分区才能使用,因此,用户通过扩展分区就可以使用5个以上的分区了.
(1)实际上,不建议用户将硬盘分为4个主分区.这是因为,假如一个20GB的硬盘, 若4个主分区占据了15GB的空间,则剩下的5GB空间完全不能使用,因为已经没有多余的分区表可以记录这些空间了.
(2)考虑到磁盘的连续性,一般建议将扩展分区放在最后面的柱面内.
(3)理论上允许一个硬盘只有1个主分区,其它空间都分配给扩展分区.
硬盘的分区主要分为基本分区(Primary Partion)和扩展分区(Extension Partion)两种,基本分区和扩展分区的数目之和不能大于四个,(根据上面的一些分区概念,是基本分区的数目不能超过4个,而扩展分区的数目最多只有1个,所以两者数目之和不能超过4个)。且基本分区可以马上被使用但不能再分区。扩展分区必须再进行分区后才能使用,也就是说 它必须还要进行二次分区。那么由扩展分区再分下去的是什么呢?它就是逻辑分区(Logical Partion),况且逻辑分区没有数量上限制。
注:通常所说的”硬盘分区”就是指修改磁盘分区表,它定义了”第n个磁盘块是从第 x个柱面到第y个柱面”.因此,当系统要读取第n个磁盘块时,就是去读硬盘上第x个柱面到第y个柱面的信息.
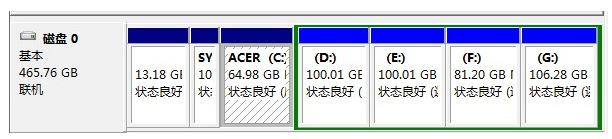
如图,咱们最常用的windows系统的分区就是这样分区的,首先分出一个主分区 (操作系统一般就是装在主分区里面),然后分了一个扩展分区,因为扩展分区不能直接使用, 所以需要在扩展分区下面将其分为若干个逻辑分区(如图所示的D、E、F、G盘就是分出来的逻辑分区)。
分区大小
实际中,给硬盘分区时,按照1G=1024M来设置,但是显示的结果都不是整数。比如:将分区设置为10G,显示的确实9.XXG。
原因是正确计算公式为
(N-1)*4+1024*N
公式中N为想要的大小,单位为GB。最终计算出来的结果为MB.
例如:想要设置分区为2G,则
(2-1)*4+1024*2=2052M
设置分区时应该为2052M
Windows和Linux分区区别
在Windows操作系统中,是先将物理地址分开(分出主分区和逻辑分区),再在分区上建立目录。 在Windows操作系统中,所有路径都是从盘符开始,如C://Program Files.
Linux正好相反,是先有目录,再将物理地址(分区)映射到目录中.在Linux操作系统中, 所有路径都是从根目录开始【/】。Linux默认可分为3个分区,分别是boot分区、swap分区和根分区.
无论是Windows操作系统,还是Linux操作系统,每个分区均可以有不同的文件系统,如FAT32、NTFS等。
对习惯于使用Dos或Windows的用户来说,有几个分区就有几个驱动器,并且每个分区都会获 得一个字母标识符,然后就可以选用这个字母来指定在这个分区上的文件和目录,它们的文 件结构都是独立的,非常好理解。但对于Linux系统来说,可不再是这样了,因为对Linux系统 用户来说,无论有几个分区,分给哪一目录使用,它归根结底就只有一个根目录,一个独立且 唯一的文件结构。Linux中每个分区都是用来组成整个文件系统的一部分,因为它采用了一种 叫”挂载”的处理方法,它的整个文件系统中包含了一整套的文件和目录,且将一个分区和一个目 录联系起来。这时要载入的一个分区将使它的存储空间在一个目录下获得。下面我们先来看看 Linux的驱动器是如何标识的。
对于IDE硬盘,驱动器标识符为“hdx~”,其中“hd”表明分区所在设备的类型,这里 是指IDE硬盘了。 “x”为盘号(a为基本盘,b为基本从属盘,c为辅助主盘,d为辅助从属盘),“~”代表分区,前四个分 区用数字1到4表示,它们是主分区或扩展分区,从5开始就是逻辑分区。例,hda3表示为第一个IDE硬 盘上的第三个主分区或扩展分区,hdb2表示为第二个IDE硬盘上的第二个主分区或扩展分区。对于SCSI 硬盘则标识为“sdx~”,SCSI硬盘是用“sd”来表示分区所在设备的类型的,其余则和IDE硬盘的表示方法 一样。如,sda1表示第一个SCSI硬盘上的第一个主分区或者扩展分区。
分区机制
主流的分区机制分为MBR和GPT两种。
MBR
MBR是放置该硬盘的信息区,称之为主引导分区(master boot recorder,MBR),相当于index;扩展分区、逻辑分区是实际文件数据放置的地方.其中,MBR是整个硬盘最重要的区域.一旦MBR物理实体损坏时, 则该硬盘就差不多报废了。
MBR(master boot record)是传统的分区机制,应用于绝对大多数使用BIOS的PC设备。
- MBR支持32bit和64bit系统
- MBR支持的分区数量有限
- MBR只支持不超过2TB的硬盘,超过2T的硬盘将只能使用2T的空间(有第三方解决方法)

- MBR结构总共占用了磁盘的头512个字节,这512个字节分为几个部分:
- 前446个字节是引导代码,引导代码就是帮助我们启动硬盘上安装的系统的,不同系统的引导代码不同。
- 接下来的四组16个字节,也就是64个字节,是我们的分区表。所以最多四个分区
- 剩下的2个字节,是启动标识。所有可引导的设备,头512字节的最后两个字节,一定是55AA。55AA是一个永久性的标志,代表硬盘是可以启动的。即便你的系统是完好无损的,如果这个启动标识被修改了的话,BIOS也是不会引导的。
- MBR分区
- 主分区:最多只能创建4个分区。
- 扩展分区:一个扩展分区会占用一个主分区的位置。
- 逻辑分区:Linux最多支持63个IDE分区和15个SCSI分区。
- 我们从上面的MBR结构可以看到,MBR的分区表只有四个条目,所以只能创建四个主分区
- 如果想要创建更多的分区,我们必须使用扩展分区和逻辑分区。
- 扩展分区会占用一个主分区的位置,而逻辑分区是基于扩展分区建立的。
- 而且扩展分区本身是不可使用的,必须在扩展分区上建立逻辑分区才能使用。
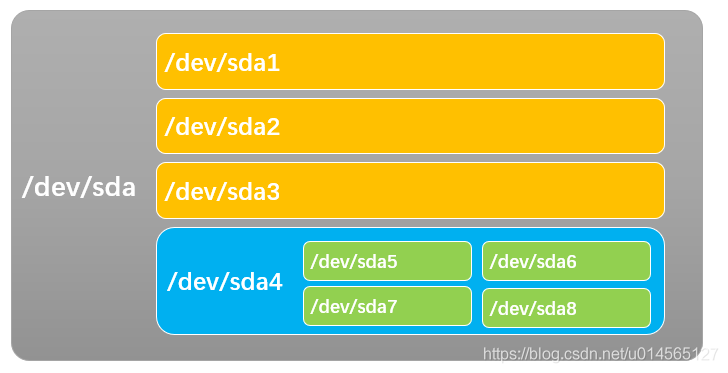
划分三个主分区sda1、sda2、sda3,将剩下的空间划分为一个扩展分区sda4,这个扩展分区本身是不可使用的,必须在这个扩展分区上建立逻辑分区,分别建立四个逻辑分区sda5、sda6、sda7、sda8。
GPT
GPT(GUID Partition Table)是一个较新的分区机制,解决了MBR的很多缺点。
- 支持超过2T的硬盘
- 向后兼容MBR
- 必须在支持UEFI的硬件上才能使用
- 必须使用64bit的系统
- Mac、Linux系统都能支持GPT分区格式
- Windows部分系统支持GPT。
因为MBR的寻址空间只有32位长,所以只能支持2T的硬盘空间。而GPT的寻址空间有64位,所以支持超过2T的磁盘,而且超过非常多,非常非常的多,GPT的存储单位是ZB,对于我们现在来讲,完全可以理解是无限大。
UEFI是取代BIOS的新一代的引导系统,全称“统一的可扩展固件接口”(Unified Extensible Firmware Interface)。硬件(通常是主板)必须支持UEFI才能使用GPT分区。
Mac和Linux原生支持GPT分区,而且Mac以MBR分区反而会变得不可使用。而Windows部分系统支持GPT。现在的服务器动辄以数十TB甚至更多的磁盘空间,如果部署Windows系统的话,在底层硬件层面上就限制住了。
物理扇区及逻辑扇区
关于物理扇区(physical setctor)与逻辑扇区,这个还得扯上扇区大小,由于近年来,随着对硬盘容量的要求不断增加,为了提高数据记录密度,硬盘厂商往往采用增大扇区大小的方法,于是出现了扇区大小为4096字节的硬盘。我们将这样的扇区称之为“物理扇区”。但是这样的大扇区会有兼容性问题,有的系统或软件无法适应。为了解决这个问题,硬盘内部将物理扇区在逻辑上划分为多个扇区片段并将其作为普通的扇区(一般为512字节大小)报告给操作系统及应用软件。这样的扇区片段我们称之为“逻辑扇区”。实际读写时由硬盘内的程序(固件)负责在逻辑扇区与物理扇区之间进行转换,上层程序“感觉”不到物理扇区的存在。
逻辑扇区是硬盘可以接受读写指令的最小操作单元,是操作系统及应用程序可以访问的扇区,多数情况下其大小为512字节。我们通常所说的扇区一般就是指的逻辑扇区。物理扇区是硬盘底层硬件意义上的扇区,是实际执行读写操作的最小单元。是只能由硬盘直接访问的扇区,操作系统及应用程序一般无法直接访问物理扇区。一个物理扇区可以包含一个或多个逻辑扇区(比如多数硬盘的物理扇区包含了8个逻辑扇区)。当要读写某个逻辑扇区时,硬盘底层在实际操作时都会读写逻辑扇区所在的整个物理扇区。
ext文件系统
硬盘分区后,还要进行文件系统的格式化,才能被操作系统使用。文件系统是一种存储和组织计算机数据的方法。文件系统格式需要操作系统支持,比如 windows使用的文件系统FAT,FAT32,NTFS等,Linux常用的文件系统ext2,ext3,ext4,xfs 等。为什么这样?因为操作系统需要设置不同文件权限,属性等等,这些需要和文件系统配合实现。
Linux文件系统实现中三个比较重要的概念:
- superblock: 记录文件系统的整体信息,包括 inode/block 的总量、使用量、剩余量, 以及文件系统的格式与相关信息等,一般位于分区第一个block。级块是很重要的,告诉linux文件系统类型,每个块的大小是多大(1024、2048 or 4096),每个块组有多少个块,inode占多少个字节等等。
- inode: 记录文件的属性,一个文件占用一个inode,同时通过inode table 记录文件所有数据块的编号。
- block: 记录文件的实际内容,若文件太大时,文件会分成多个block存储。block大小一般为1k、2k或4k。
可以看出文件系统的元数据和数据是单独存储的,inode和block都有唯一的编号,对于ext文件系统inode和block编号在格式化时候已经确定好。
EXT2概述
Ext2 (Linux second extended file system, ext2fs) 是Linux传统文件系统,是通过对Minix的文件系统进行扩展而得到的,其存取文件的性能极好。相对来说ext2比较简单,支持工具比较多,我们从通过学习ext2文件系统来深入理解linux文件系统。
我们来看看一个硬盘分区,用ext2文件系统格式化后变成一个什么样的结构?我们用一张图说明一下:
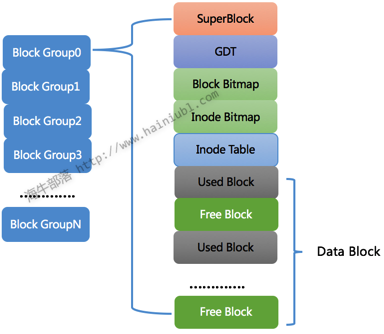
可以看出ext2是将分区划分成了很多block group,而不是将所有的 inode和block放到一起管理。你可以想想分区几百G或几T的容量,那inode和block的数量惊人,很难管理。所以将分区划分成block组来管理。
Superblock
记录文件系统的整体信息,是非常重要的,如果superblock坏了,那整个文件系统也就不能用了。一般情况superblock 的大小为 1024b,记录主要信息:
- inode/block 总量
- inode/block 的使用情况
- block 和 inode 的大小 (block 为 1, 2, 4K,inode 为 128bytes 或 256bytes)
- filesystem 的挂载时间、最近一次写入时间、挂载标志等等相关信息
- Block Group0 的 Superblock 是主Superblock,其它组按照策略放置它的副本,为了破损时能够恢复。
GDT(group descriptor table)
GDT 可以理解为是组描述符的一个数组,有多少组就有多少个元素。
inode bitmap
bitmap是个数据结构,标志位表的方式记录每个inode是否已经被使用。你可以简单理解为如果这个inode的表记位为1表示已经被使用,如果文件删除了,inode会被收回,那它的表记位变成0.
block bitmap
和inode bitmap是一样的道理,用来描述整个块组中哪些块已用哪些块空闲。块位图本身占一个块,其中的每个bit代表本块组的一个block,这个bit为1代表该块已用,为0表示空闲可用。假设格式化时block大小为1KB,这样大小的一个块位图就可以表示1024*8个块的占用情况,因此一个块组最多可以有10248个块。
data block
数据块是实际存储数据的地方,ext2文件系统支持block大小有1K、2K和4K,每个block有一个唯一编号,在格式化的时候就这些都被确定好了。block使用上还是有些限制的:
大小和数据格式化后不能在改变,除非重新格式化
每个block只能放置一个文件的数据,不能多个文件共享
文件数据占用block的数据等于 file size/ block size + file size % block size == 0 ? 0 : 1, 也就是说数据占不满一个block也不能被别的文件使用的了。这就造成空间浪费。
inode table
inode table用于在格式化时,分配好的inode列表
我们重点讲讲inode,这是ext2文件系统的核心。inode一般为128bytes,存储好多重要信息,我们看看这张图:
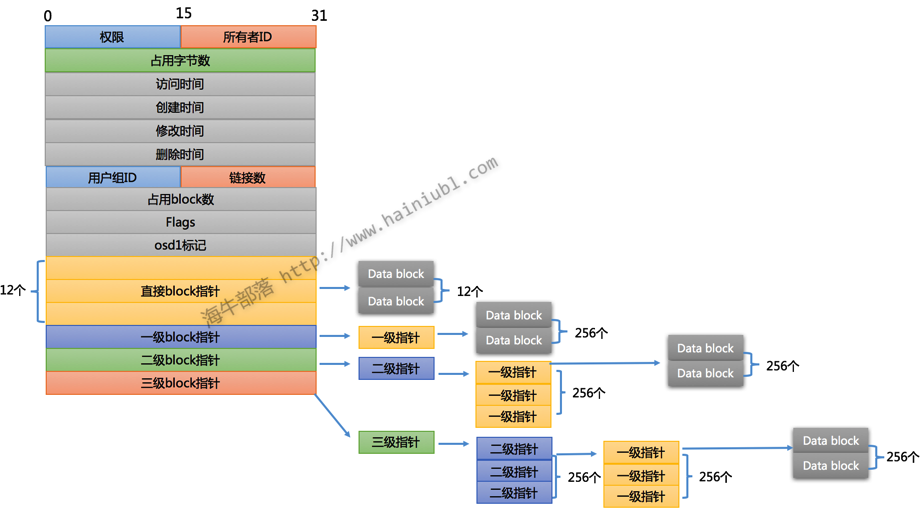
这张图是以inode 128bytes,block 1k 大小画的,可以看出,inode存储了文件的所有相关属性:权限,时间,数据块的列表等等。
inode 要存这么多信息,一个block ID 就是4个字节,一个文件 成千上万的block ID 怎么存的下?所以 inode采用分层的方法存储 block ID列表,这样就能存储很多 block ID。
细心的朋友要问,这样存储也是有限制的?是的,ext2 存储最大文件 16G,怎么算的?
假设沾满所有的block ID空间: 121k + 2561k + 2562561k + 256256256*1k = 16GB
如果想存的文件更大,格式化的时候可以增加block块大小,如果block 块大小为 4k,则最大文件可以存储 2TB,但是小文件比较多时会浪费一定空间。
ext4
另外这里面有一个非常显著的问题,对于大文件来讲要多次读取硬盘才能找到相应的块,这样访问速度就会比较慢。为了解决这个问题,ext4引入了一个新的概念,叫作Extents,比方说一个文件大小为128M,如果使用4k大小的块进行存储,需要32k个块,如果按照ext2或者ext3那样散着放数量太大了,但是Extents可以用于存放连续的块,也就是说可以把128M放在一个Extents里面。这样对大文件的读写性能提高了,文件碎片也减少了。Exents如何来存储呢?它其实会保存成一棵树,如下所示:

树有一个个的节点,有叶子节点也有分支节点。每个节点都有一个头,ext4_extent_header可以用来描述某个节点
eh_entries 表示这个节点里面有多少项。这里的项分两种,如果是叶子节点,这一项会直接指向硬盘上的连续块的地址,我们称为数据节点;如果是分支节点,这一项会指向下一层的分支节点或者叶子节点,我们称为索引节点 ext4_extent_idx。这两种类型的项的大小都是 12 个 byte。
除了根节点,其他的节点都保存在一个块 4k 里面,4k 扣除 ext4_extent_header 的 12 个 byte,剩下的能够放 340 项,每个 extent 最大能表示 128MB 的数据,340 个 extent 会使你的表示的文件达到 42.5GB。这已经非常大了,如果再大,我们可以增加树的深度
目录是特殊的文件
每个文件都会占用一个 inode,且可依据文件内容的大小来分配多个 block 给该文件使用。目录是特殊的文件,当我们在Linux下的文件系统建立一个目录时,文件系统会分配一个 inode 与至少一块 block给该目录。inode记录相关元数据信息,block记录目录下面的文件名或目录名及相应的inode。
读取目录数一个递归过程,从根节点开始,读到根节点的inode内容,并依据该 inode 读取根目录的 block 内的文件名数据,再一层一层的往下读,直到读取到相应的文件或目录数据。
journal日志
作为日志文件系统,ext4使用journal来对文件系统操作进行记录,它和文件系统数据是分开进行管理的,当我们写入文件系统时,会先把最新的数据保存在journal区域中,然后再写入到真正文件系统中,当多次写入时会不停的更新journal中的数据内容,以保持最新的写入数据。这样做保证了文件系统的可靠性,并且当文件系统出现问题时,利于分析问题。
journal block的创建
那么这个journal区域是在什么时候创建的呢?
使用Linux系统中的mkfs.ext4命令创建一个ext4文件系统(实际上调用的是mke2fs工具),从下面的输出log可以看到,对应的ext4文件系统会创建journal block。
$ dd if=/dev/zero of=test.img bs=1M count=512
$ mkfs.ext4 test.img
mke2fs 1.42.13 (17-May-2015)
Discarding device blocks: 完成
Creating filesystem with 131072 4k blocks and 32768 inodes
Filesystem UUID: 6482c469-a195-48d0-bed4-2033baec77c4
Superblock backups stored on blocks:
32768, 98304
Allocating group tables: 完成
正在写入inode表: 完成
Creating journal (4096 blocks): 完成
Writing superblocks and filesystem accounting information: 完成
可以通过如下命令选项对journal的区域大小进行配置:
-J size=64
这个选项传入参数的单位是M字节,默认为64M大小。我们修改为32M可以使用如下命令:
mkfs.ext4 -J size=32 test.img
通过挂载上该文件系统镜像后进入挂载目录查看df信息,可以发现原本生成的一个512M的文件系统大小,只剩余472M的总容量,那么其他的容量在哪里?
实际上这里显示的总容量并没有包含journal区域和superblock以及superblock备份区域,因此它显示的总容量是少于原本镜像的大小的。
$ df . -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/loop0 472M 396K 436M 1% /media/xiehaocheng/test
可以使用dumpe2fs来查看该文件系统相关的metadata信息:
dumpe2fs 1.42.13 (17-May-2015)
Filesystem volume name: <none>
Last mounted on: <not available>
Filesystem UUID: d6193181-b0c1-41b4-8c4e-4629636209fa
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 32768
Block count: 131072
Reserved block count: 6553
Free blocks: 120719
Free inodes: 32757
First block: 0
Block size: 4096
Fragment size: 4096
Reserved GDT blocks: 31
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Flex block group size: 16
Filesystem created: Mon Aug 19 19:19:45 2019
Last mount time: Mon Aug 19 19:20:43 2019
Last write time: Mon Aug 19 19:20:43 2019
Mount count: 1
Maximum mount count: -1
Last checked: Mon Aug 19 19:19:45 2019
Check interval: 0 (<none>)
Lifetime writes: 32 MB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256
Required extra isize: 28
Desired extra isize: 28
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 0c1a2d41-bbf6-4a73-a2fc-93125b58521a
Journal backup: inode blocks
Journal features: (none)
日志大小: 32M
Journal length: 8192
Journal sequence: 0x00000002
Journal start: 1
Group 0: (Blocks 0-32767) [ITABLE_ZEROED]
Checksum 0x5742, unused inodes 8181
主 superblock at 0, Group descriptors at 1-1
保留的GDT块位于 2-32
Block bitmap at 33 (+33), Inode bitmap at 37 (+37)
Inode表位于 41-552 (+41)
30673 free blocks, 8181 free inodes, 2 directories, 8181个未使用的inodes
可用块数: 2095-32767
可用inode数: 12-8192
Group 1: (Blocks 32768-65535) [INODE_UNINIT, BLOCK_UNINIT, ITABLE_ZEROED]
Checksum 0x4075, unused inodes 8192
备份 superblock at 32768, Group descriptors at 32769-32769
保留的GDT块位于 32770-32800
Block bitmap at 34 (bg #0 + 34), Inode bitmap at 38 (bg #0 + 38)
Inode表位于 553-1064 (bg #0 + 553)
32735 free blocks, 8192 free inodes, 0 directories, 8192个未使用的inodes
可用块数: 32801-65535
可用inode数: 8193-16384
Group 2: (Blocks 65536-98303) [INODE_UNINIT, ITABLE_ZEROED]
Checksum 0xe120, unused inodes 8192
Block bitmap at 35 (bg #0 + 35), Inode bitmap at 39 (bg #0 + 39)
Inode表位于 1065-1576 (bg #0 + 1065)
24576 free blocks, 8192 free inodes, 0 directories, 8192个未使用的inodes
可用块数: 73728-98303
可用inode数: 16385-24576
Group 3: (Blocks 98304-131071) [INODE_UNINIT, ITABLE_ZEROED]
Checksum 0xc611, unused inodes 8192
备份 superblock at 98304, Group descriptors at 98305-98305
保留的GDT块位于 98306-98336
Block bitmap at 36 (bg #0 + 36), Inode bitmap at 40 (bg #0 + 40)
Inode表位于 1577-2088 (bg #0 + 1577)
32735 free blocks, 8192 free inodes, 0 directories, 8192个未使用的inodes
可用块数: 98337-131071
可用inode数: 24577-32768
journal挂载选项
关于挂载选项可以参考内核文档,
linux/Documentation/filesystems/ext4.txt:
data=journal All data are committed into the journal prior to being
written into the main file system. Enabling
this mode will disable delayed allocation and
O_DIRECT support.
data=ordered (*) All data are forced directly out to the main file
system prior to its metadata being committed to the
journal.
data=writeback Data ordering is not preserved, data may be written
into the main file system after its metadata has been
committed to the journal.
和journal有关的如上所述,主要分为三种数据写入方式:
-
journal方式
所有数据(data+metadata)在被写入文件系统前,都要先写入到journal区域,可靠性很好,但是性能却最差。 -
ordered方式
这种方式不用记录data,但是需要在data写入文件系统之后,把metadata写入到journal区域,相比前一种提高了性能,稍微降低的可靠性。 -
writeback
这种方式不用记录data,只需要把metadata写入到journal区域,但不保证data已经写入文件系统,所以它的可靠性最差。
默认挂载方式采用的是ordered方式,这种方式是另外两种的一种平衡,使得可靠性和性能都能达到一个均衡。