为什么使用雪花算法
- 数据库自增id,在分表的情况下会导致重复
- uuid不是自增的,对于 innodb会导致页分裂和碎片的问题
- 雪花算法是按时间戳递增的,分布式id生成算法

使用
雪花算法的实现非常多,各大厂都有自己的实现,本文以mybatisplus为例
添加依赖
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-core</artifactId>
<version>3.3.2</version>
</dependency>
调用
System.out.println(IdWorker.getId());//1546384181118812162
原理
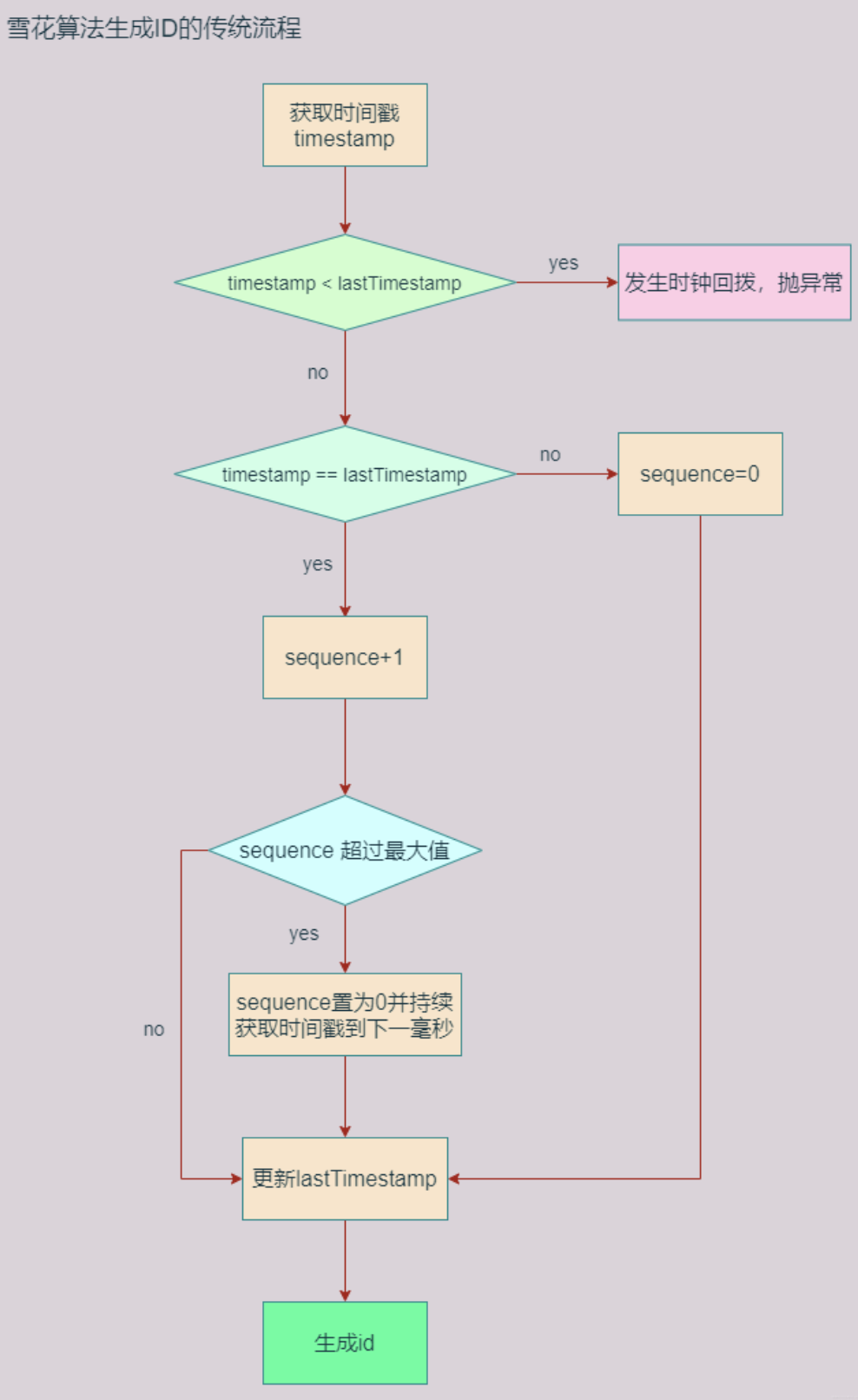
问题
时间回拨问题
因为Snowflake是在单位时间(毫秒)内序列递增的,当存在时间回拨时,序列已经是当前时间戳下的序列值了,已经无法获取到回拨时间点那块的序列值,在存在时间回拨时,无法生成时间戳
发生时间回拨的原因
- 人为原因,把系统环境的时间改了。
- 有时候不同的机器上需要同步时间,可能不同机器之间存在误差,那么可能会出现时间回拨问题
解决方案
- 回拨时间小的时候,不生成 ID,循环等待到时间点到达。
- 上面的方案只适合时钟回拨较小的,如果间隔过大,阻塞等待,肯定是不可取的,因此要么超过一定大小的回拨直接报错,拒绝服务,或者有一种方案是利用拓展位,回拨之后在拓展位上加1就可以了,这样ID依然可以保持唯一。但是这个要求我们提前预留出位数,要么从机器id中,要么从序列号中,腾出一定的位,在时间回拨的时候,这个位置 +1。
- 另一种方案是在上次时间戳序列上+1
第一位为什么不使用?
在计算机的表示中,第一位是符号位,0表示整数,第一位如果是1则表示负数,我们用的ID默认就是正数,所以默认就是0,那么这一位默认就没有意义。
机器位怎么用?
机器位或者机房位,一共10 bit,如果全部表示机器,那么可以表示1024台机器,如果拆分,5 bit 表示机房,5bit表示机房里面的机器,那么可以有32个机房,每个机房可以用32台机器。
twepoch表示什么?
由于时间戳只能用69年,我们的计时又是从1970年开始的,所以这个twepoch表示从项目开始的时间,用生成ID的时间减去twepoch作为时间戳,可以使用更久。
-1L ^ (-1L << x) 表示什么?
表示 x 位二进制可以表示多少个数值,假设x为3:
在计算机中,第一位是符号位,负数的反码是除了符号位,1变0,0变1, 而补码则是反码+1:
从上面的结果可以知道,-1L其实在二进制里面其实就是全部为1,那么 -1L 左移动 3位,其实得到 1111 1000,也就是最后3位是0,再与-1L异或计算之后,其实得到的,就是后面3位全是1。-1L ^ (-1L << x) 表示的其实就是x位全是1的值,也就是x位的二进制能表示的最大数值。
时间戳比较
在获取时间戳小于上一次获取的时间戳的时候,不能生成ID,而是继续循环,直到生成可用的ID,这里没有使用拓展位防止时钟回拨。
前端直接使用发生精度丢失
如果前端直接使用服务端生成的long 类型 id,会发生精度丢失的问题,因为 JS 中Number是16位的(指的是十进制的数字),而雪花算法计算出来最长的数字是19位的,这个时候需要用 String 作为中间转换,输出到前端即可。