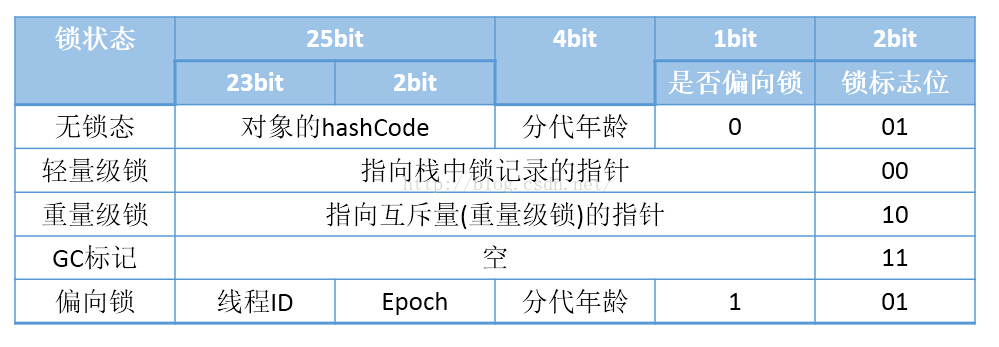
java对象Mark Word
32位Header Mark Word
即32bit,4个字节
64位Header Mark Word
|------------------------------------------------------------------------------|--------------------|
| Mark Word (64 bits) | State |
|------------------------------------------------------------------------------|--------------------|
| unused:25 | identity_hashcode:31 | unused:1 | age:4 | biased_lock:1 | lock:2 | Normal |
|------------------------------------------------------------------------------|--------------------|
| thread:54 | epoch:2 | unused:1 | age:4 | biased_lock:1 | lock:2 | Biased |
|------------------------------------------------------------------------------|--------------------|
| ptr_to_lock_record:62 | lock:2 | Lightweight Locked |
|------------------------------------------------------------------------------|--------------------|
| ptr_to_heavyweight_monitor:62 | lock:2 | Heavyweight Locked |
|------------------------------------------------------------------------------|--------------------|
| | lock:2 | Marked for GC |
|------------------------------------------------------------------------------|--------------------|
即64bit,8个字节
Jol
Jol可用于查看java object内存情况。
ClassLayout.parseInstance(test).toPrintable()
内存存储
数据的高字节与低字节
一个正常的二进制数值,左边为高字节,右边为低字节,如00000000 01010101中00000000为高字节01010101为低字节
地址的高地址与低地址
地址位是从前往后依次递增的,如地址位为0x0001,0x0002,0x0003.....0x0010等,其中0x0001为低地址位,0x0010为高地址位
大小端
内存之所以有大小端,原因为:超过1个字节的存储,比如short,int等,该如何组织存储单元?数据的高位放在内存的高地址还是低地址?都需要有明确的定义。
大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;如0x01 00 00 04
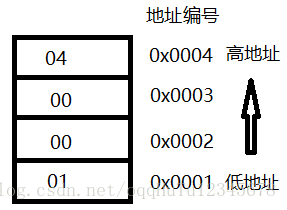
小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。如0x01 00 00 04

hashcode
com.kevin.header.ObjectHeaderTest object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 0f 8a 82 (00000001 00001111 10001010 10000010) (-2104881407)
4 4 (object header) 75 00 00 00 (01110101 00000000 00000000 00000000) (117)
8 4 (object header) 9f c0 00 f8 (10011111 11000000 00000000 11111000) (-134168417)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
- 其中
00000000 00000000 00000000 01110101 10000010 10001010 00001111可计算出hashcode值 - 上述
00000000 00000000 00000000 01110101 10000010 10001010 00001111采用的是小端模式 - java是按大端或小端存储 可通过
ByteOrder.nativeOrder()查看
如果自己实现hashcode方法,则不会被记录在header中;由于64位jdk中前25位未使用,所以Object hashcode值永远为正数,实际经测试确未发现负数的情况
从header头获取hashcode
/**
* 手动计算对象o的hashcode
*
* @param o
*/
public static int produceHashCode(Object o) {
int hashCode = 0;
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
Unsafe unsafe = (Unsafe) field.get(null);
for (long index = 7; index > 0; index--) {
// 取Mark Word中的每一个Byte进行计算
//此处"& 0xFF"的目的是保留原二进制,去掉负数时补位的1,否则通过进行"|"时会将补位的高位均或为1,即数据不准(无论hashcode是何值,均会得负值,因为高位肯定会|为1)
hashCode |= (unsafe.getByte(o, index) & 0xFF) << ((index - 1) * 8);
//hashCode |= (unsafe.getByte(o, index) ) << ((index - 1) * 8);
}
String manualHashCode = Long.toHexString(hashCode);
System.out.println(String.format("manualHashCode : 0x%s," + hashCode, manualHashCode));
} catch (Exception e) {
e.printStackTrace();
}
return hashCode;
}